
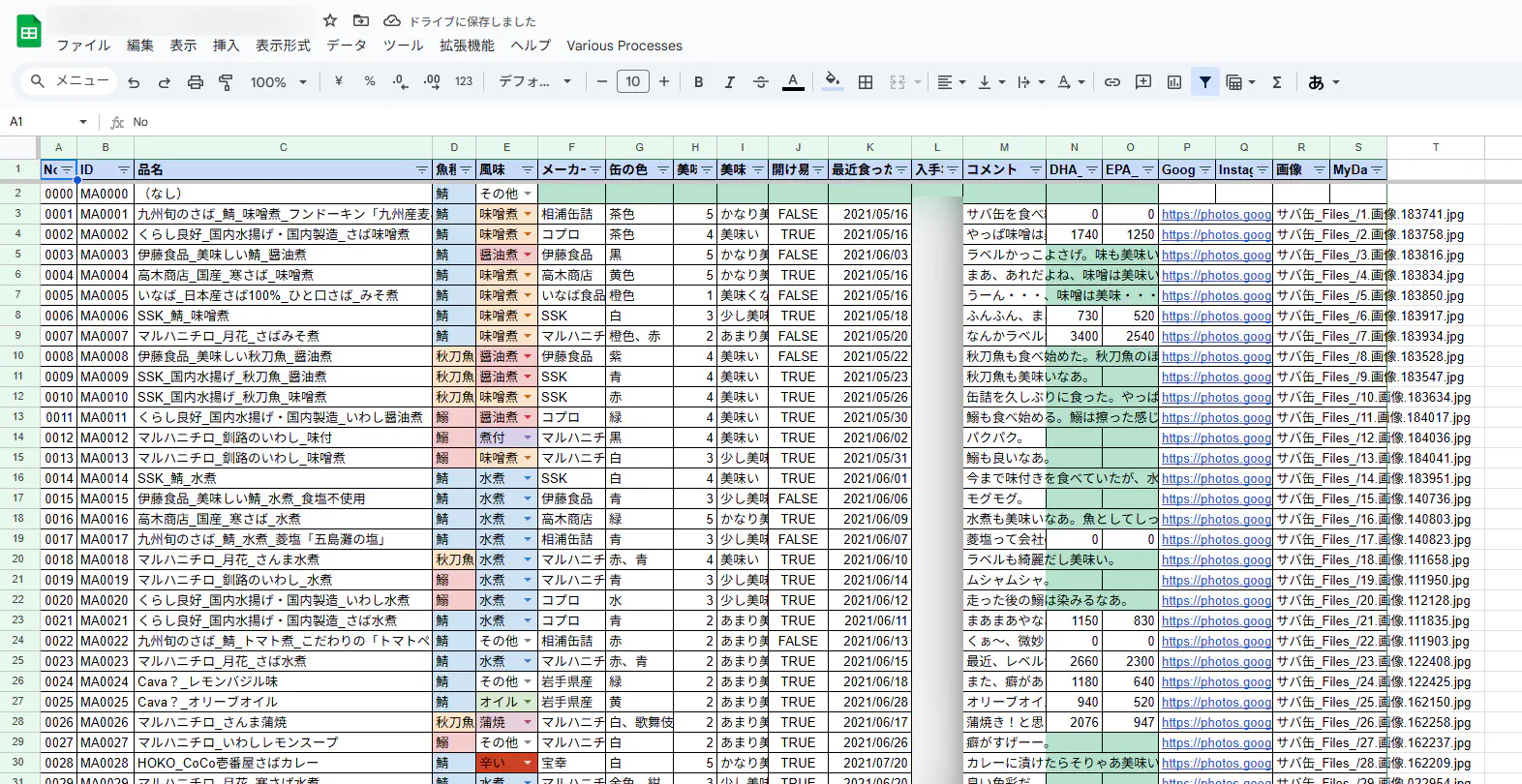
はじまり
なんだこれ?
サバ缶だ。
Pythonでtsvをまとめて記事にする。
僕は、個人的に日常的に食べているサバ缶をGoogleスプレッドシートに記録しています。そんな書き溜めてきたサバ缶のレビュー記事を楽に作ろうと思いました。
そこで、PythonのPandas等でデータを整理して、レビュー記事を出力するスクリプトを作る過程を紹介したいと思います。
ちなみに、2024年版のサバ缶のまとめの記事はこちらになります。

スプレッドシートにあるデータをtsvにする。
まずは、スプレッドシートにあるデータをtsvファイルにします。スプレッドシートからコピーしたデータをメモ帳に貼り付けると、基本的にはtsv形式で貼り付けられるので、そのままメモ帳の内容をtsvファイルとして保存します。
Google Colabで開発する。
今回のPythonの開発には、まずはGoogle Colabを使いました。Colabに先程保存したtsvファイルをアップロードします。
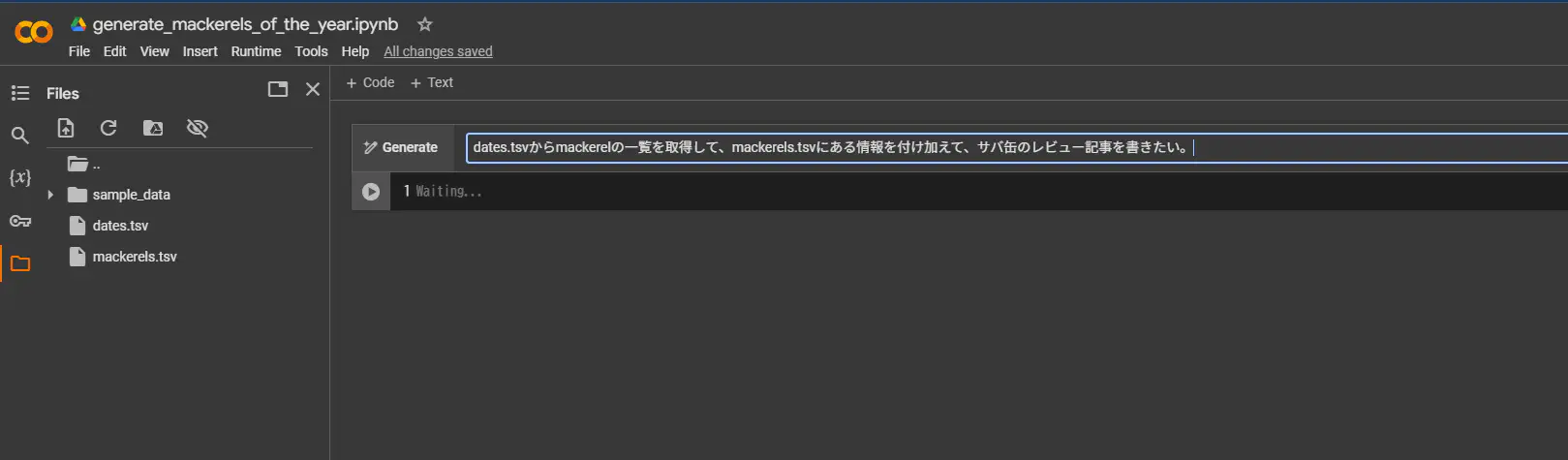
そして、Google Colab上にGeminiだかGemmaだか分かりませんが何かいるので、スクリプトを作ってもらいます。
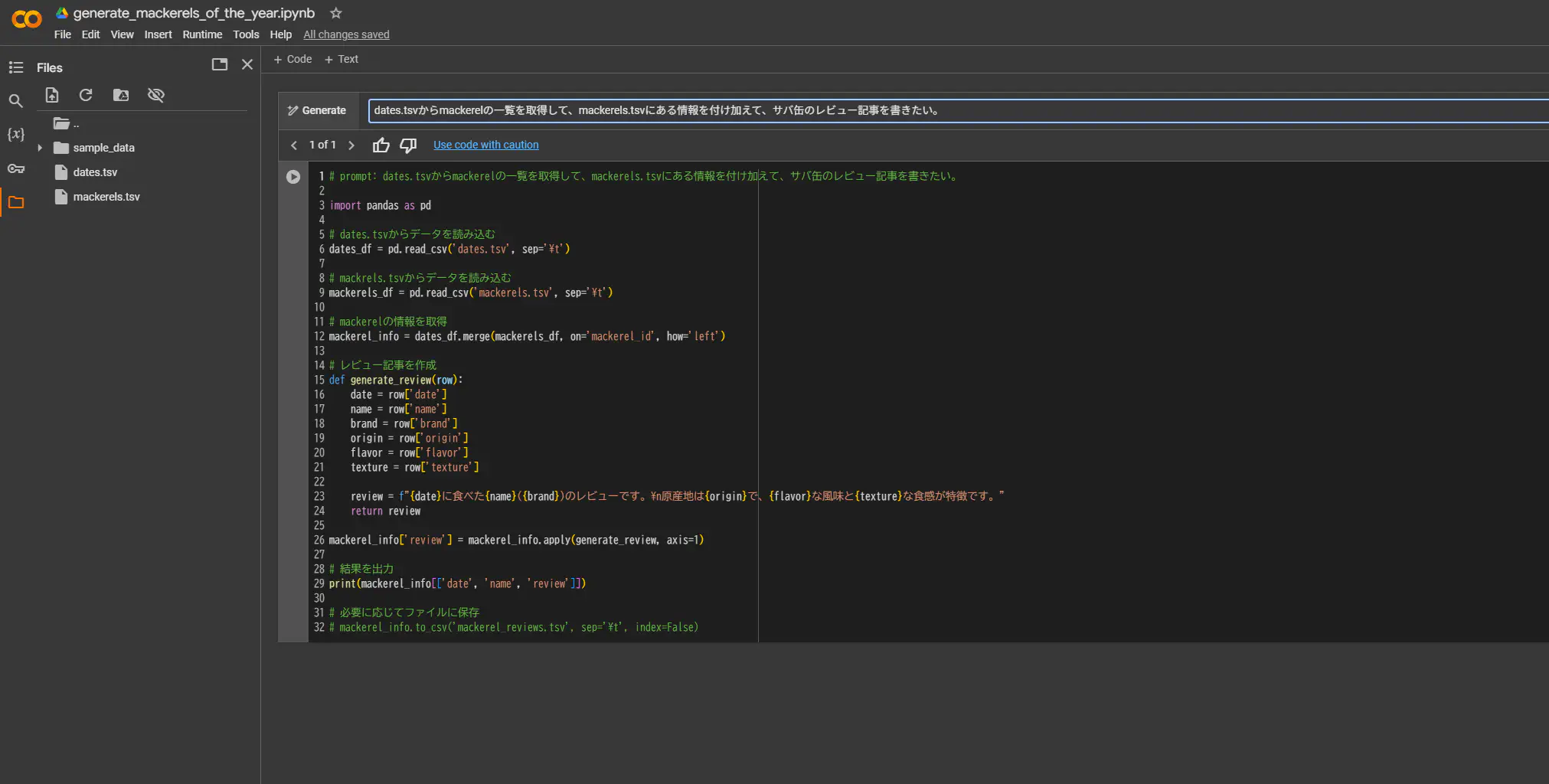
Google Colabにいる生成AIは、tsvファイルの中身を全く確認していないようです。不整合な部分を自分で直します。
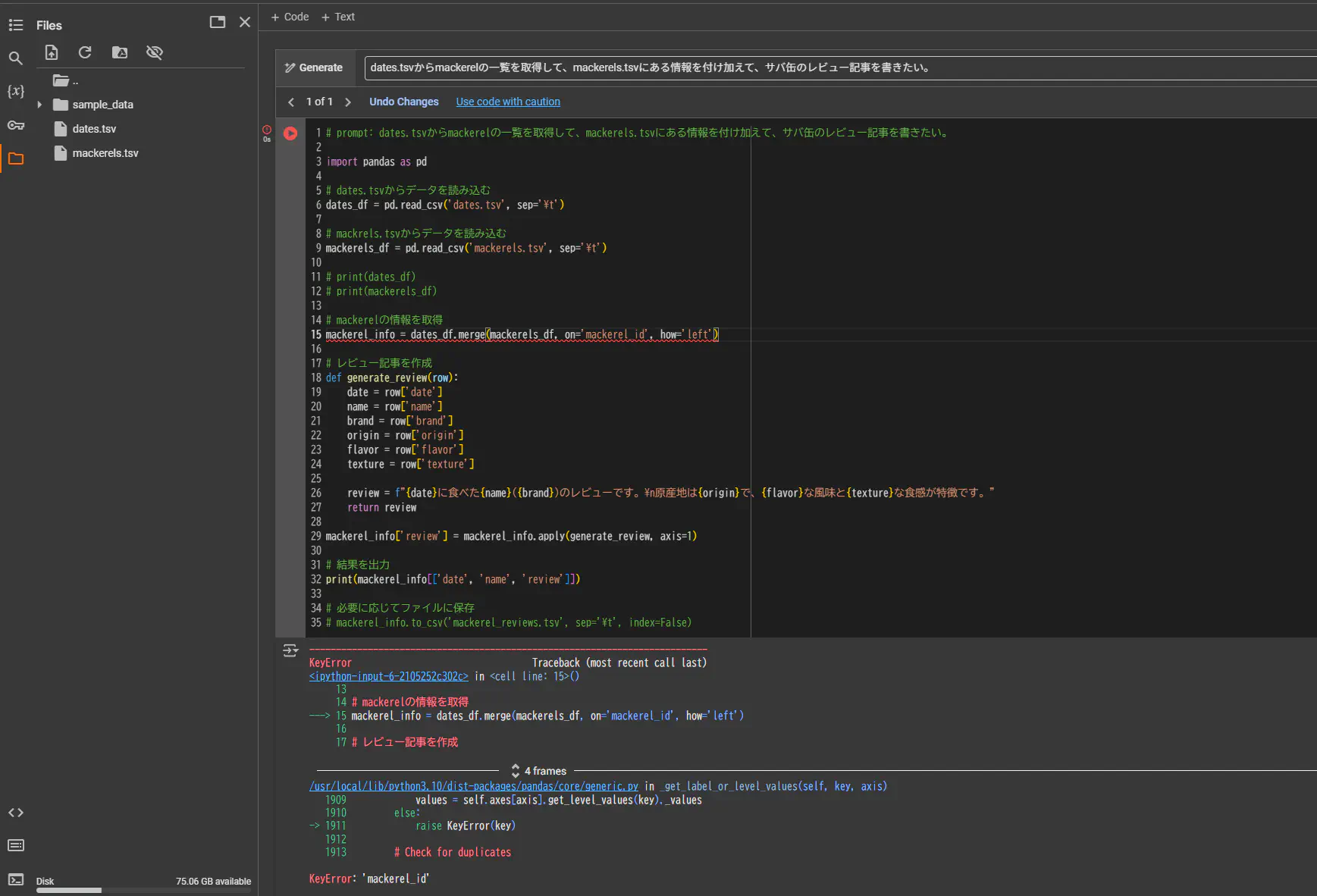
とりあえず動きそうです。
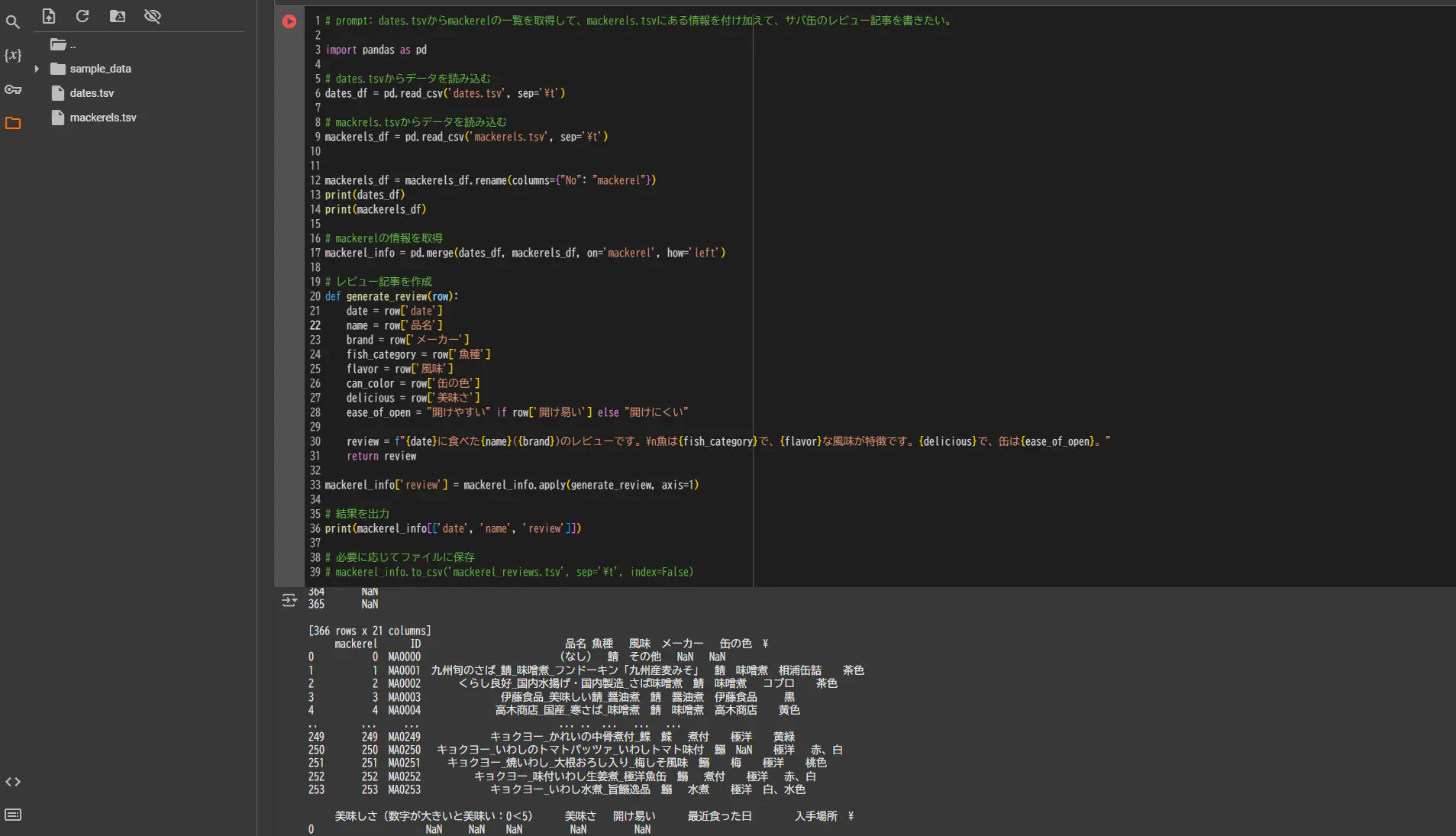
Pandasで整理する。
今回は、Pandasを使ってtsv形式のデータをデータフレームとして整理していきます。
今回はこのように整理しました。「dates.tsv」には「mackerel」のフィールドが最低限必要です。
# prompt: dates.tsvからmackerelの一覧を取得して、mackerels.tsvにある情報を付け加えて、サバ缶のレビュー記事を書きたい。
from typing import Union
import pandas as pd
# load data from dates.tsv
dates_df = pd.read_csv("dates.tsv", sep="\t")
# load data from mackrels.tsv
mackerels_df = pd.read_csv("mackerels.tsv", sep="\t")
mackerels_df = mackerels_df.rename(columns={"No": "mackerel"})
print(dates_df)
print(mackerels_df)
# mackerelの情報を取得
dates_df = dates_df.query("mackerel != 0")
dates_df.drop_duplicates(subset="mackerel")
dates_df.dropna(subset=["mackerel"], inplace=True)
mackerel_info = pd.merge(dates_df, mackerels_df, on="mackerel", how="left")
# Create Heading 2
def generate_h2(row: Union[pd.Series, pd.DataFrame]) -> str:
"""
Generates a level 2 heading for a mackerel review article.
:param row: A pandas Series containing the data for the review.
It should have columns "number_for_article", "品名", and "メーカー".
:type row: pd.Series
:raises TypeError: if row is not a pd.Series
:raises KeyError: if row is missing any of the required columns
:returns: The level 2 heading string.
:rtype: str
:Example:
>>> generate_h2(pd.Series({'number_for_article': 1, '品名': 'サバ缶', 'メーカー': 'メーカーA'}))
'## 1. サバ缶(メーカーA)'
"""
if not isinstance(row, pd.Series):
raise TypeError("row must be a pandas Series")
number_for_article = row["number_for_article"]
name = row["品名"]
brand = row["メーカー"]
return f"## {number_for_article}. {name}({brand})"
# レビューを作成
def generate_review(row: Union[pd.Series, pd.DataFrame]) -> str:
"""Generates a review article for canned mackerel.
:param row: Data used to create the review article.
:type row: Union[pd.Series, pd.DataFrame]
:raises TypeError: if row is not a pd.Series or pd.DataFrame
:returns: The review article.
:rtype: str
:Example:
>>> generate_review(pd.Series({'date': '2023-10-27', 'name': 'Canned Mackerel', 'brand': 'Maker'}))
'## 1. Canned Mackerel (Maker)\\n\\n![]()\\n\\nEaten on 2023-10-27, "Canned Mackerel" made by Maker.\\nThe fish is...\\n'
"""
if not isinstance(row, (pd.Series, pd.DataFrame)):
raise TypeError("row must be a pandas Series or DataFrame")
date = row["date"]
name = row["品名"]
brand = row["メーカー"]
fish_category = row["魚種"]
flavor = row["風味"]
can_color = row["缶の色"]
delicious = row["美味さ"]
dha = row["DHA_content(mg)"]
epa = row["EPA_content(mg)"]
ease_of_open = "開けやすい" if row["開け易い"] else "開けにくい"
comment = row["コメント"]
review = f"{date}に食べた{brand}製の「{name}」です。\n魚は{fish_category}で、{flavor}な風味と{can_color}の缶の色が特徴です。{delicious}で、缶は{ease_of_open}です。\nオメガ3脂肪酸の含有量の目安としては、DHAが{dha}mgで、EPAが{epa}mgでした。\n{comment}"
h2 = row["h2"]
image = "![]()"
review = f"{h2}\n\n{image}\n\n{review}"
return review
mackerel_info["number_for_article"] = range(1, len(mackerel_info.index) + 1)
mackerel_info["h2"] = mackerel_info.apply(generate_h2, axis=1)
mackerel_info["review"] = mackerel_info.apply(generate_review, axis=1)
mackerel_info["md_item"] = mackerel_info.apply(generate_review, axis=1)
# 結果を出力
print("micsellanious info of mackerel_info is the following...")
print(mackerel_info[["number_for_article", "date", "name", "h2", "review"]])
print("mackerel_info_image is the following...")
print(mackerel_info["画像"])レビュー記事の内容をNotionに投稿する。
レビュー記事の内容が出来上がったら、次にその内容を簡単に貼り付けられるようにします。
Markdownのまま(Markdownの文字列)で貼り付けても、Heading 2の要素に出来なかったりするので、Notionの「Append block children」APIを使って全ての要素を貼り付けられるようにします。


そして、NotionからWordPressのエディタの方に貼り付けて下記の記事が出来上がりました。
まとめ
今回は、Googleスプレッドシート上にあるデータをtsvファイルにして、PythonとPandasでtsvデータを整理して、Notionのページに反映する処理を実装しました。
今回作った処理を完全に自動化して、月次の記事も作れるようにしてみたいですね。
おしまい
この量が一瞬で書けちゃったなあ
貯めてきた甲斐があった・・・
以上になります!

コメント