
はじまり
・・・というものが出来てしまったな。
作れてしまいました
Clineに自分のブログ記事に関してまとめてもらった。
さすがにそろそろ生成AIに記事を書いてもらいたくなりました。
そこで今回は、Clineに自分のブログ記事の文章の文体や内容の特徴などをまとめてもらって、そのまとめを基に記事を執筆してもらいました。
以下の記事を参考にさせていただきました。

資料を作る。
まずは、Clineに「writing-style.md」という文体や記事の特徴をまとめた資料を作ってもらいます。そのために、その資料を作るための記事の文章が入ったMarkdownを沢山作っていきましょう。
自分は記事を書く際にNotionにメモるようにしているので、Notionからページ群をエクスポートします。エクスポートすると、沢山Markdownファイルが手に入ります。
/home/nov/My_Tasks xxxxxxxxxxxx45458198b099a00e647c/target_markdowns
|--3DMarkに関する情報をまとめた_20241205_kinkinbeer135ml xxxxxxxxxxxxxxxdb2a1eb4e0d63af6b.md
|--40万円で手に入れた2つのPCの性能のベンチマークを比較する(第1回:3DMarkとCinebe xxxxxxxxxxxxxxb9be3f129b4642f3c.md
|--40万円で手に入れた2つのPCの性能のベンチマークを比較する(第2回:Satisfactoryや xxxxxxxxxxxxxx8ea2d6ca55426b306b.md
|--B650_Steel_Legend_WiFiで使えるASRock Polychrome RGBの入 xxxxxxxxxxxxxx9a79c2147b8f4f3b.md
|--ChocolateyでWindowsに一気にインストールする_20250105_kinkinbee xxxxxxxxxxxxxx83b2a4c2bdf6c0465c.md
...NotionでエクスポートしたMarkdownの中には、ページのプロパティや自分がメモした情報などが載っていて余分な情報が混ざっているので、本当に欲しい情報を抽出します。自分の場合は、記事を書く際に必ず「# Content\\n\\n## はじまり\\n」という正規表現が引っ掛かる部分以降に記事の本文をバックアップするようにしているので、その目印を基に文章を抽出していきます。
シェル関数で抽出します。
function move_files_from_list() {
local func_name="move_files_from_list"
# ヘルプ表示
if [[ "$1" == "--help" ]]; then
echo "[INFO] ${func_name}: 使用方法"
echo " ${func_name} <ファイルリスト> <移動先ディレクトリ> [デフォルト拡張子]"
echo ""
echo "説明:"
echo " 指定されたファイルリストに記載されているファイルを移動先ディレクトリに移動します。"
echo " ファイル名に拡張子がない場合は、指定されたデフォルト拡張子が追加されます。"
echo ""
echo "パラメータ:"
echo " <ファイルリスト> 移動対象ファイル名が記載されたテキストファイル(必須)"
echo " <移動先ディレクトリ> ファイルの移動先ディレクトリ(必須)"
echo " [デフォルト拡張子] 拡張子のないファイル名に追加する拡張子(省略時は .md)"
echo ""
echo "使用例:"
echo " ${func_name} ファイルリスト.txt /path/to/destination"
echo " ${func_name} ファイルリスト.txt /path/to/destination .txt"
return 0
fi
# 引数チェック
if [ $# -lt 2 ] || [ $# -gt 3 ]; then
echo "[ERROR] ${func_name}: 引数の数が不正です"
echo "[INFO] ${func_name}: 使用法を確認するには「${func_name} --help」を実行してください"
return 1
fi
local file_list=$1
local dest_dir=$2
local default_ext=".md" # デフォルトの拡張子は.md
local moved_count=0 # 移動したファイル数をカウント
# 引数で拡張子が指定されている場合は上書き
if [ $# -eq 3 ]; then
default_ext=$3
# 拡張子の先頭にドットがなければ追加
if [[ ! $default_ext =~ ^\. ]]; then
default_ext=".$default_ext"
fi
fi
# 移動先ディレクトリの存在確認
if [ ! -d "$dest_dir" ]; then
echo "[ERROR] ${func_name}: 移動先ディレクトリ '$dest_dir' が存在しません"
return 1
fi
# ファイルリストの存在確認
if [ ! -f "$file_list" ]; then
echo "[ERROR] ${func_name}: ファイルリスト '$file_list' が見つかりません"
return 1
fi
echo "[INFO] ${func_name}: ファイルの移動を開始します..."
# ファイルリストを読み込んで移動
while IFS= read -r filename || [ -n "$filename" ]; do
# 空行をスキップ
if [ -z "$filename" ]; then
continue
fi
# 拡張子の確認と追加
local actual_filename="$filename"
if [[ ! "$filename" =~ \.[^./]+$ ]]; then
actual_filename="${filename}${default_ext}"
echo "[INFO] ${func_name}: 拡張子なしファイル '$filename' に '$default_ext' を追加しました: '$actual_filename'"
fi
# ファイルの存在確認
if [ -f "$actual_filename" ]; then
mv "$actual_filename" "$dest_dir"
echo "[INFO] ${func_name}: '$actual_filename' を '$dest_dir' に移動しました"
((moved_count++))
else
echo "[ERROR] ${func_name}: '$actual_filename' が見つからないためスキップします"
fi
done < "$file_list"
# 移動したファイル数を表示
if [ $moved_count -eq 0 ]; then
echo "[INFO] ${func_name}: 移動したファイルはありません"
else
echo "[INFO] ${func_name}: 移動処理が完了しました - 合計 $moved_count 個のファイルを移動しました"
fi
return 0
}
function find_content_files() {
local func_name="find_content_files"
# 改行を含むパターンを正しく定義
# Perl正規表現モード(-P)では \n が改行を表す
local search_pattern="# Content\\n\\n## はじまり\\n"
# ヘルプ表示
if [[ "$1" == "--help" ]]; then
echo "[INFO] ${func_name}: 使用方法"
echo " ${func_name} <ディレクトリ> [拡張子]"
echo ""
echo "説明:"
echo " 指定されたディレクトリ内で、特定のコンテンツパターンを含むファイルを検索します。"
echo " 検索対象は「# Content」の後に3つの改行、その後に「## はじまり」が続くパターンです。"
echo ""
echo "パラメータ:"
echo " <ディレクトリ> 検索対象のディレクトリパス(必須)"
echo " [拡張子] 検索対象のファイル拡張子(省略時は .md)"
echo ""
echo "使用例:"
echo " ${func_name} ~/documents"
echo " ${func_name} ~/projects .txt"
return 0
fi
# 引数チェック
if [ $# -lt 1 ] || [ $# -gt 2 ]; then
echo "[ERROR] ${func_name}: 引数の数が不正です"
echo "[INFO] ${func_name}: 使用法を確認するには「${func_name} --help」を実行してください"
return 1
fi
local dir_path="$1"
local extension=".md" # デフォルト拡張子
# 拡張子が指定されている場合は上書き
if [ $# -eq 2 ]; then
extension="$2"
# 拡張子の先頭にドットがなければ追加
if [[ ! $extension =~ ^\. ]]; then
extension=".$extension"
fi
fi
# ディレクトリの存在確認
if [ ! -d "$dir_path" ]; then
echo "[ERROR] ${func_name}: ディレクトリ '$dir_path' が存在しません"
return 1
fi
echo "[INFO] ${func_name}: '$dir_path' ディレクトリ内の '$extension' ファイルを検索中..."
# 結果を格納する変数
local found_files=0
# ディレクトリ内のファイルを検索
for file in "$dir_path"/*"$extension"; do
# ファイルが存在しない場合のエラー処理
if [ ! -f "$file" ]; then
echo "[INFO] ${func_name}: '$extension' 拡張子のファイルが見つかりません"
return 0
fi
# ファイル内容を検索
if grep -Pzq "$search_pattern" "$file" 2>/dev/null; then
echo "$file"
((found_files++))
fi
done
# 結果の表示
if [ $found_files -eq 0 ]; then
echo "[INFO] ${func_name}: パターンに一致するファイルが見つかりませんでした"
else
echo "[INFO] ${func_name}: パターンに一致するファイルが $found_files 件見つかりました"
fi
return 0
}
function extract_content_files() {
# 関数名をローカル変数に格納
local funcName="${FUNCNAME[0]}"
# --helpパラメータの確認
if [[ "$1" == "--help" ]]; then
echo "[INFO] ${funcName}: 利用方法:"
echo " ${funcName} <対象ディレクトリ> [拡張子]"
echo " <対象ディレクトリ> : 処理対象のディレクトリ"
echo " [拡張子] : ファイルの拡張子(省略時は \".md\")"
echo ""
echo "[INFO] ${funcName}: 使用例:"
echo " ${funcName} /path/to/directory .md"
return 0
fi
# パラメータ数のチェック
if [ $# -lt 1 ]; then
echo "[ERROR] ${funcName}: 対象ディレクトリが指定されていません。--help を参照してください。" >&2
return 1
fi
local target_dir="$1"
local ext="${2:-.md}"
# 対象ディレクトリが存在するかチェック
if [ ! -d "$target_dir" ]; then
echo "[ERROR] ${funcName}: 指定されたディレクトリ '$target_dir' が存在しません。" >&2
return 1
fi
# extracted_contentsディレクトリを作成
local output_dir="${target_dir}/extracted_contents"
mkdir -p "$output_dir"
if [ $? -ne 0 ]; then
echo "[ERROR] ${funcName}: '$output_dir' の作成に失敗しました。" >&2
return 1
fi
echo "[INFO] ${funcName}: '$output_dir' を作成しました。"
# 対象ディレクトリ内の拡張子が一致する各ファイルに対して処理を実施
for file in "${target_dir}"/*"${ext}"; do
# 通常のファイルのみ処理
if [ ! -f "$file" ]; then
continue
fi
# ファイル内からマーカー以降の内容を取得
# マーカーは以下のように記載されているとする:
# # Content
#
# ## はじまり
# 以降すべてのテキストを抽出(マーカーも含む)
local content
content=$(perl -0777 -ne 'if(/(# Content\s*\n\s*\n## はじまり\s*\n.*)/s){print $1}' "$file")
if [ -z "$content" ]; then
echo "[ERROR] ${funcName}: ファイル '$file' 内に指定マーカーが見つかりませんでした。" >&2
continue
fi
local basefile
basefile=$(basename "$file")
local output_file="${output_dir}/${basefile}"
# 抽出した内容を新規ファイルに出力
echo "$content" > "$output_file"
if [ $? -ne 0 ]; then
echo "[ERROR] ${funcName}: '$output_file' への出力に失敗しました。" >&2
else
echo "[INFO] ${funcName}: '$file' を処理し、'$output_file' に出力しました。"
fi
done
}
find_content_files ./
# txtファイルに書き込むためのファイル一覧が表示されるので、markdown_list.txtにメモる。
move_files_from_list markdown_list.txt ./target_markdowns
cd target_markdowns
extract_content_files ./これで、まとめるために欲しい資料が手に入りました。
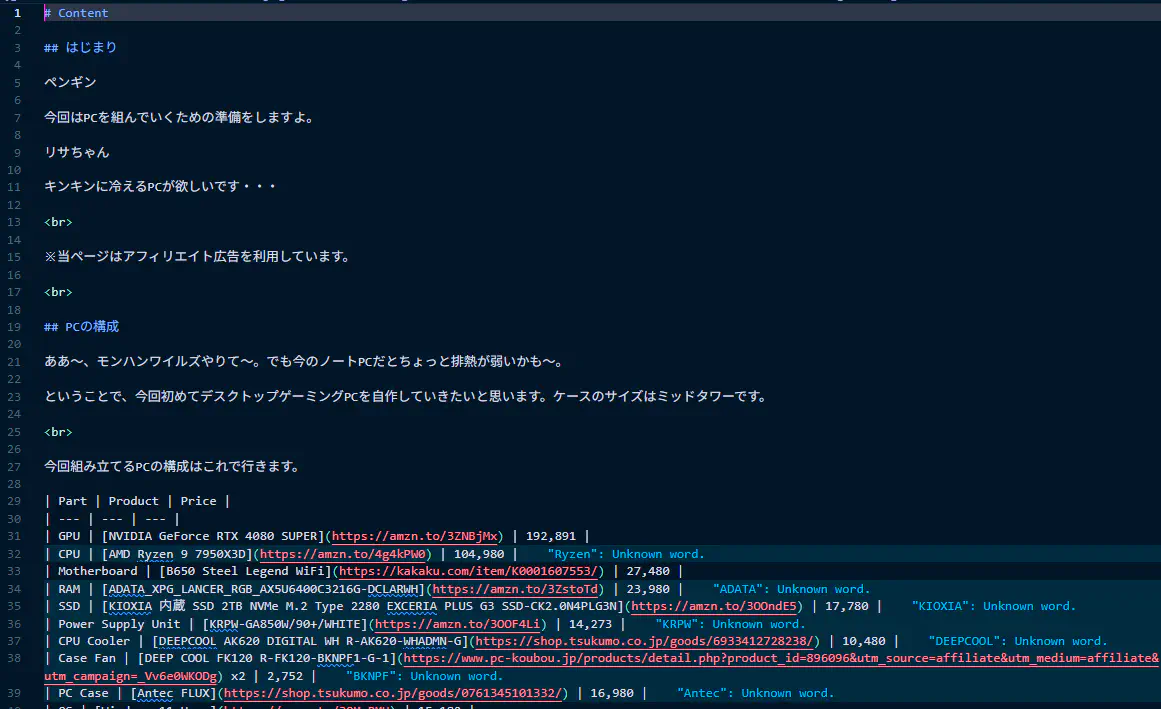
文体と特徴をまとめる。
それでは次に、Clineに「writing-style.md」という文体や記事の特徴をまとめた資料を作ってもらいます。前の工程で抽出した資料が78件ぐらいあったような覚えがあります。それらの資料を適当にAIに読んでもらって、Markdown形式でまとめてもらいます。
まとめてもらうためのプロンプトがこんな感じです。
私は日本のエンジニアです。
kinkinbeer135ml といいます。もし私について知っていたら、以下でその知識を使っても構いません。
~/My_Tasks\ xxxxxxxxxxxxxxxxxxxxxxxxx0e647c/target_markdowns/extracted_contents/* 以下は自分がブログに書いた記事です。
AIが書いたとバレない範囲で、ブログの記述を自動化したいです。
記事一覧から私の技術の方向性を抽出し、そこからランダムに読んでください。最低限、10記事は読んでください。
そこから私の人格と文体を抽出して、それを ~/My_Tasks\ xxxxxxxxxxxxxxxxxxxxxxxxx0e647c/target_markdowns/generated_contents/writing-style.md に抽出してください。
最終的には、それをベースに記事を執筆してもらいます。最初、OpenAIのo1で作ってもらおうと思ったのですが、o1は扱えるトークン長が短いらしい。
429 Request too large for o1 in organization org-XXXXXXXXXXXXXXXXXXXXX on tokens per min (TPM): Limit 30000, Requested 32394. The input or output tokens must be reduced in order to run successfully. Visit https://platform.openai.com/account/rate-limits to learn more.そしたら次に、Claude APIで3.7 Sonnetで出力してみました。こっちであればかなり進めることが出来ました。まあでもしかし、最初の出力量だとブログ記事作成用の資料としてはボリュームが少なかったので、追加でプロンプトを与えて内容を補填していきました。
その分析に使ったMarkdownファイルに記載されている内容のまとめを「## 分析済み記事の要約」という見出しの中にまとめてください。
その分析に使ったMarkdownファイルに記載されている内容のそれぞれの記事構成のパターンを「## 分析済み記事の要約」という見出しの中に追記しください。
「プログラミング関連の記事の特徴」という見出しを作って、その中に全体的な記事の特徴を追記して。自分で修正したりもしていって・・・、そして一旦、この内容の「writing-style.md」が出来上がりました。ゆくゆくは、記事のジャンルごとに作り並べていきたいですがとりあえずこれで行ってみましょう。
# 書き手の文体と技術方向性
本ブログ記事群から以下の特徴が抽出されました:
## 文体・トーン
- **カジュアルかつ親しみやすい**
読者に対してフレンドリーな語り口が特徴。たとえば、記事中に「リサちゃん」や「ペンギン」といった愛称を使い、軽妙なユーモアが散りばめられています。
- **詳細な技術解説**
各記事は技術的な背景や実装方法、仕様などを丁寧に解説しており、専門的な読者に向けた深い内容が含まれます。図表やコード例を適宜交え、論理的に説明しています。
- **率直で実践的**
自身の経験や実際のテスト結果、比較結果をもとに、率直な意見を述べるスタイルです。実際の動作確認やパフォーマンス測定に基づく分析が重視されています。
## 技術の方向性
- **クラウドおよびサーバーレス技術**
Cloud SQL、Cloud Functions、GAS(Google Apps Script)など、クラウドサービスを利用したシステム構築や自動化に関する記事が多く見られます。
- **Chrome拡張機能やウェブアプリ開発**
ブラウザ拡張機能、ウェブAPI連携、Notion連携など、フロントエンドおよびバックエンドの統合開発の事例が記されています。
- **システム自動化とスクリプト技術**
PowerShell、Bash、Python、Golangなど、さまざまなプログラミング言語を用いた自動化やスクリプト処理の具体例が豊富です。
- **ハードウェア評価およびベンチマーク分析**
3DMarkをはじめとするGPU、CPU、統合グラフィックスの性能評価、最新技術(DirectX、Vulkan、DLSS、FSR、XeSS)の検証記事が掲載され、ハードウェアに対する深い洞察が見受けられます。
## 全体的な印象
- 複数の技術分野を横断し、実用性と楽しさを融合させたスタイルを採用。
- 技術的な解説だけでなく、個人的な視点や感想を交え、読者に身近に感じてもらえる記事作成が行われている。
- 最新技術に対する好奇心と実験的なアプローチが顕著で、読者に次の技術への期待を持たせる工夫がなされています。
## 追加分析(サンプル読解に基づく考察)
- **文体とアプローチの柔軟性**
記事タイトルや内容から、筆者は技術的な精度と共に、カジュアルさや実験的アプローチを大切にしていることが読み取れます。体験談や実際のテストに基づいた具体的な例が多く、読者に実践的な知識を提供しています。
- **多角的な技術観**
クラウド、サーバーレス、スクリプト技術、ハードウェアベンチマークなど、多岐にわたる分野を扱っており、常に最新技術に挑戦し、幅広い視野で議論を展開している印象です。
- **実用性と実証性の重視**
コード例や操作手順、実際の性能測定結果など、実用的な情報が豊富に提供されており、読者がすぐに実践に移せる工夫が随所に見られます。
## 人格特徴
- **謙虚さと自信の融合**
記事全体からは、常に謙虚な姿勢を保ちながらも、自身の技術や経験に基づく確固たる自信が読み取れます。
- **熱意と探究心**
技術に対する深い探究心と、常に最新の情報を追い求める情熱が感じられ、実験的なアプローチが随所に見られます。
- **ユーモアと親しみやすさ**
カジュアルな語り口や愛称の使用により、技術的に難解な内容でも親しみやすく、読者にやさしく寄り添う温かさがあります。
- **実践志向**
実際の動作確認やパフォーマンス測定に基づいた具体的な知見を提供する姿勢から、理論だけでなく実践も重視する現実的な人柄が表れています。
## 文体の特徴的な要素
### 記事構成
- **キャラクター対話による導入と締めくくり**
ほぼすべての記事が「リサちゃん」と「ペンギン」または「135ml」というキャラクターの会話で始まり、同様の会話で締めくくられています。この対話形式により、技術的な内容に親しみやすさを加えています。
- **視覚的な説明の重視**
スクリーンショット、図表、コードブロックを多用して説明を補強しています。特に操作手順やUIの説明では、視覚的な情報を積極的に取り入れています。
- **段落間の空白**
段落間に`<br>`タグを入れて読みやすさを向上させています。これにより、密度の高い技術情報でも読者が読み進めやすくなっています。
### 言葉遣いと表現
- **読者への語りかけ**
「〜ですね」「〜でしょう」「〜したいと思います」など、読者に直接語りかけるような表現を多用しています。これにより、一方的な解説ではなく、読者との対話を意識した文体になっています。
- **感情表現の挿入**
「オオオッ・・・」「アレッ・・・」など、感情を表す表現を適宜挿入し、筆者の驚きや発見を読者と共有しています。
- **多様な表現レベルの混在**
「言わずもがな」「雲泥の差」などの少し堅めの表現と、「なるほどなるほど」などの会話的な表現が混在しており、硬軟取り混ぜた文体となっています。
- **断定を避ける表現**
「〜かもしれません」「〜でしょうか」など、断定を避ける表現を使うことで、読者に考える余地を残し、押し付けがましさを軽減しています。
- **説明の締めくくり方**
「〜なわけです」「〜というわけです」など、説明を締めくくる際の特徴的な表現があります。これにより、説明に明確な区切りをつけ、読者の理解を促しています。
### 実用的な要素
- **関連商品の紹介**
記事の最後に関連商品のリンクを紹介することが多く、読者が実際に試してみたいと思った際の参考になるよう配慮しています。
- **段階的な説明**
複雑な技術的内容を、基本から応用へと段階的に説明する構成が多く見られます。初心者から上級者まで幅広い読者層に対応できるよう工夫されています。
## プログラミング関連の記事の特徴
- **コードブロックの効果的な使用**
プログラミング関連の記事では、コードブロックを多用して実際のコード例を示しています。単なるコードの提示だけでなく、コードの前後に解説を加え、読者が理解しやすいように工夫されています。また、コードの重要な部分には強調表示やコメントを入れることが多いです。
- **エラーメッセージの提示と解決方法**
実際に遭遇したエラーメッセージを提示し、その原因と解決方法を丁寧に解説しています。「こんなエラーが出たら、こうすれば解決できる」という実践的なアドバイスが豊富です。
- **ステップバイステップの実装手順**
複雑な実装も、段階的に分解して説明しています。各ステップで何が行われているのかを明確にし、読者が自分のプロジェクトに応用しやすいように配慮されています。
- **実際のユースケースや応用例**
抽象的な説明だけでなく、実際のユースケースや応用例を提示することで、技術の実用性を示しています。特に、自身のプロジェクトでの使用例を交えることで、説得力のある内容になっています。
- **関連するライブラリやフレームワークの紹介**
メインの技術だけでなく、関連するライブラリやフレームワークも適宜紹介しています。これにより、読者が技術スタック全体を理解しやすくなっています。
- **注意点や落とし穴の説明**
実装時に陥りがちな落とし穴や注意点を明示的に説明しています。「ここでハマりました」「この部分は特に注意が必要です」といった表現で、読者が同じ問題に遭遇することを防いでいます。
- **パフォーマンスや最適化に関する考察**
単に動作するコードを提示するだけでなく、パフォーマンスや最適化に関する考察も加えています。「こうすればもっと効率的になる」「この方法だとメモリ使用量が少なくて済む」といった実用的なアドバイスが含まれています。
- **代替手段や比較検討**
一つの解決策だけでなく、複数の代替手段を提示し、それぞれのメリット・デメリットを比較検討しています。これにより、読者が自分のプロジェクトに最適な方法を選択できるようになっています。
## ゲーム関連の記事の特徴
- **実践的なTipsの提供**
ゲーム関連の記事では、自身の経験に基づいた実践的なTipsや効率化のコツを提供しています。特にパルワールドなどのゲームでは、プレイ経験から得られた知見を詳細に解説しています。
- **ゲームと技術の融合**
ゲームプレイの楽しさと技術的な側面(ベンチマーク、パフォーマンス最適化など)を融合させた内容が特徴的です。ゲームを単なる娯楽としてではなく、技術検証の場としても捉えている姿勢が見られます。
## 分析済み記事の要約
今回の分析では、以下の記事を読み込み、文体と人格の特徴を抽出しました:
### 1. 3DMarkに関する情報をまとめた記事
ファイル名:「3DMarkに関する情報をまとめた_20241205_kinkinbeer135ml 153194df981d80fdb2a1eb4e0d63af6b.md」
3DMarkというベンチマークソフトウェアの各種テスト(Steel Nomad、Fire Strike、Time Spy、Port Royalなど)について詳細に解説し、DirectX、Vulkan、DLSS、FSR、XeSSなどの技術についても説明しています。
**記事構成**:
```
## はじまり
## 3DMarkの情報をまとめたい
## 3DMarkの各種テスト
### Steel Nomad(DirectX 12環境の高負荷ベンチマークテスト)
### Steel Nomad Stress Test(高負荷ストレステスト)
### CPU Profile(CPUのマルチコア性能を評価)
### Fire Strike(DirectX 11環境のテスト)
### Time Spy(DirectX 12環境のテスト)
### Speed Way(DirectX 12 Ultimateとレイトレーシング性能の検証)
### Night Raid(DirectX 12環境でArm版Windows向けの軽量テスト)
### Solar Bay(モバイル環境も考慮したレイトレーシングテスト)
### Port Royal(レイトレーシングと伝統的なレンダリングのテスト)
### Wild Life(モバイルデバイス向けのクロスプラットフォームテスト)
### NVIDIA DLSS feature test(DLSSの効果を数値で確認)
### AMD FSR feature test(FSRの効果を数値で確認)
### Intel XeSS feature test(XeSSの効果を数値で確認)
## 各種テストに出てきた単語のまとめ
### DirectX 11とDirectX 12
### Direct3D
### Direct3D機能レベル
### Arm
### Vulkan
### TAA(Temporal Anti-Aliasing)
### NVIDIA DLSS
### AMD FSR
### XeSS
## まとめ
## おしまい
```
### 2. Google AI Studioの使い方とGeminiとの比較
ファイル名:「Google_AI_Studioの使い方。Geminiと比較してみた。_20241020_kinki 129194df981d80fd98bffe200fb5da8f.md」
Google AI Studioの基本的な使い方、APIキーの発行方法、プロンプトの実行方法、OCR機能などを解説し、Geminiとの機能比較を行っています。
**記事構成**:
```
## はじまり
## 最近、生成AIを使っていなかったもので・・・
## Google AI Studioとは?
## 使ってみる
### APIキーの発行
### 実際にプロンプトしてみる。
### プリプロンプトできる。
### プロンプトした内容をGoogleドライブに保存できる。
### プロンプトギャラリーというものもある。
## 画像のOCRを試してみる。
## Geminiと比較してみる。
### Geminiの場合。
### Google AI Studioの場合。
### 比較まとめ
## GASでAPIキーを使ってみる。
## まとめ
## 作業のお供に。
## おしまい
```
### 3. パルワールドの拠点作りに関するTips
ファイル名:「【Palworld】生産効率の高い拠点を作るために気を付ける10のこと_20250108_kinki xxxxxxxxxxxxxxxxxxxxxxxxxe077ad.md」
ゲーム「パルワールド」で効率的な拠点を作るための10のコツを紹介。作業適性の高いパルの活用法、設備の積み重ね方、作業指示台の設置など、実践的なTipsが詳細に解説されています。
**記事構成**:
```
## はじまり
## パルワールドの拠点の作業効率を上げる。
## 1. 作業適性が高いパルを働かせる。
## 2. パルがベッドにたどり着けないようにする。
## 3. 農園を積み重ねる。
## 4. 採掘場も積み重ねる。
## 5. ライン工場も積み重ねられる。
## 6. 作業指示台を設置する。
## 7. 「その他」カテゴリの設備を設置する。
## 8. アイテム取り出し機を使う。
## 9. 商人を設置する。
## 10. 原油抽出機は油田に2つ設置可能。
## まとめ
## Palworldを快適に
## おしまい
```
### 4. Google Apps Scriptの基本的な使い方
ファイル名:「【GAS】Google Apps Scriptの基本的な使い方・始め方_20241029_kinki xxxxxxxxxxxxxxxxxxxxxxxxx2356cf.md」
GASの始め方、プロジェクトの作成方法、コードの実行方法、Googleサービスとの連携方法、トリガーの設定方法などを初心者向けに解説しています。
**記事構成**:
```
## はじまり
## Google Apps Scriptとは?
## Google Apps Scriptの始め方
### Googleアカウントの準備
### Google Apps Scriptのプロジェクトの作成
### コードの実行
### Googleサービスとの連携
## 関数のトリガーの設定
## まとめ
## 設定に関するその他の記事
## おしまい
```
### 5. Cloud Functionsのデプロイ前のテスト
ファイル名:「【Cloud Functions】デプロイ直前にランタイム環境変数を利用した関数のテストは出来な xxxxxxxxxxxxxxxxxxxxxxxxx25a6f1.md」
Cloud Functionsをデプロイする前のテストに関する問題と、ランタイム環境変数を利用した関数のテストについての解説です。
**記事構成**:
```
## はじまり
## まず、何が起きてるんだ
## 実際にテストしてみる
## 解決策
## まとめ
## おしまい
```
### 6. Notionに画像を貼り付ける際の注意点
ファイル名:「【気を付けろ】GoogleドキュメントからNotionに貼り付けた画像はリンクで貼られる_202 xxxxxxxxxxxxxxxxxxxxxxxxx86ae0ef.md」
GoogleドキュメントからNotionに画像を貼り付ける際に発生する問題点と、デジタル資産を失わないための対策について警鐘を鳴らしています。
**記事構成**:
```
## はじまり
## これから同じことをしようとしている人に向けての警鐘
## 何が起こったのか。
### Notionに移動した画像が表示されない・・・。
## 原因は何か。
## 対策は?
## まとめ
## おしまい
```
### 7. PowerShellでcwebpを使ったJPG圧縮とPDF変換
ファイル名:「【PowerShell】Cwebpで圧縮したJPGだとiTextSharpでPDFに変換出来な xxxxxxxxxxxxxxxxxxxxxxxxxc21b8ae.md」
cwebpで圧縮したJPG画像がiTextSharpでPDF変換できない問題とその解決方法について、PowerShellのコードを交えて解説しています。
**記事構成**:
```
## はじまり
## まずは何が起きたのか。
## 原因は何か。
## 解決策は?
## まとめ
## おしまい
```
### 8. PydanticのBaseModelのバリデーション
ファイル名:「【Python】Pydanticのvalidatorが非推奨だからfield_validator xxxxxxxxxxxxxxxxxxxxxxxxxe8636.md」
PythonのPydanticライブラリを使った型アノテーションとバリデーションの実装方法について、validatorからfield_validatorへの移行を含めて解説しています。
**記事構成**:
```
## はじまり
## PydanticのBaseModelのバリデーションをする
## 「クラス」メソッドと「インスタンス」メソッドの分別を付ける。
## validatorが非推奨になった。
## field_validatorを使う。
## まとめ
## おしまい
```
### 9. GitHubでmainブランチに誤ってプッシュする問題
ファイル名:「【Chrome拡張機能開発】GitHubでmainブランチにいる時に目立たせて気付きたい_202 xxxxxxxxxxxxxxxxxxxxxxxxxe0fba7e.md」
GitHubでmainブランチに誤ってプッシュしてしまう問題に対処するためのChrome拡張機能開発について解説しています。
**記事構成**:
```
## はじまり
## まず、何が起きてるんだ
## Chrome拡張機能を作る
## 実装する
## 動作確認
## まとめ
## おしまい
```
### その他の技術記事
ファイル名:「【Python】開発時に導入して個人的に便利だった事柄まとめ_20241116_kinkinbee xxxxxxxxxxxxxxxxxxxxxxxxx4c1d2d5ef3f.md」など
上記以外にも、PowerShellを使った画像処理、Python開発環境の設定、Notion APIの活用法など、多岐にわたる技術トピックについての記事を分析しました。
**記事構成の共通パターン**:
```
## はじまり(キャラクター対話)
## 主題の提示
## 本文(複数の見出しで構成)
## まとめ
## (関連商品紹介)
## おしまい(キャラクター対話)
```
これらの記事は、技術的な内容を詳細かつ親しみやすく解説しており、実践的な知識と筆者の経験に基づいた洞察が豊富に含まれています。また、ほぼすべての記事が「リサちゃん」と「ペンギン」または「135ml」というキャラクターの会話で始まり、同様の会話で締めくくられているという特徴的な構成を持っています。
実際にAIに書かせる。
それでは「writing-style.md」を基に、実際にAIにブログ記事を書かせてみます。WordPressであれば、Notionに一度Markdownを貼り付けてブロックに変換してから、WordPressエディタに貼り付け直すのが良さそうです。
このプロンプトで書いてもらいます。
~/My_Tasks\ xxxxxxxxxxxxxxxxxxxxxxxxx0e647c/target_markdowns/generated_contents/writing-style.md を参考に、Pythonのモジュールであるtypingの使い方を説明する記事を書いて。~/My_Tasks\ xxxxxxxxxxxxxxxxxxxxxxxxx0e647c/target_markdowns/generated_contents内に出力して。
それでは出力結果をどうぞ・・・
はじまり
ねえねえ、ペンギンさん。最近Pythonのコードを書いていたら、`typing`っていうモジュールをよく見かけるんだけど、これって何なの?
オオッ、いい質問だね!typingモジュールは、Pythonに型ヒントを追加するためのものだよ。動的型付け言語であるPythonに、静的型チェックの恩恵をもたらしてくれるんだ。
型ヒント?それって何か便利なの?
もちろん!コードの可読性が上がるし、IDEの補完機能が強化されるし、型チェッカーを使えば実行前にバグを見つけられるようになるんだ。今日はそのtypingモジュールの使い方を詳しく解説していくよ!
Pythonのtypingモジュールとは?
Pythonは動的型付け言語として知られていますが、Python 3.5からtypingモジュールが導入され、コードに型ヒント(Type Hints)を追加できるようになりました。これにより、静的型付け言語のような型チェックの恩恵を受けられるようになったのです。
typingモジュールは以下のような利点をもたらします:
- コードの可読性と自己文書化の向上
- IDEやエディタの補完機能と型チェック機能の強化
- mypy等の型チェッカーによる静的解析でのバグ早期発見
- リファクタリングの安全性向上
重要なのは、型ヒントはあくまで「ヒント」であり、Pythonの実行時の動作には影響しないということです。型チェックは外部ツールによって行われます。
基本的な型ヒントの使い方
まずは基本的な型ヒントの書き方から見ていきましょう。
def greeting(name: str) -> str:
return f"こんにちは、{name}さん!"
age: int = 30
is_active: bool = True
height: float = 175.5
上記の例では:
name: str– 引数nameが文字列型であることを示しています> str– 関数の戻り値が文字列型であることを示しています- 変数宣言時にも
: 型名の形式で型ヒントを付けられます
基本的な型としては、str、int、float、bool、bytesなどがあります。これらはPythonの組み込み型なので、typingモジュールをインポートする必要はありません。
複合型の使い方
より複雑なデータ構造には、typingモジュールの複合型を使います。
from typing import List, Dict, Tuple, Set, Optional, Union
# リスト
numbers: List[int] = [1, 2, 3, 4, 5]
# 辞書
user_info: Dict[str, str] = {"name": "太郎", "email": "taro@example.com"}
# タプル
coordinates: Tuple[float, float] = (35.6895, 139.6917) # 緯度、経度
# 固定長と可変長のタプル
triple: Tuple[int, int, int] = (1, 2, 3) # 固定長(3要素)
numbers_tuple: Tuple[int, ...] = (1, 2, 3, 4, 5) # 可変長
# セット
unique_ids: Set[int] = {1, 2, 3, 4, 5}
# Optional型(値またはNone)
maybe_name: Optional[str] = None # strまたはNone
# Union型(複数の型のいずれか)
id_or_name: Union[int, str] = "user123" # intまたはstr
Python 3.9以降では、組み込み型のジェネリクス表記が簡略化されました:
# Python 3.9以降
numbers: list[int] = [1, 2, 3, 4, 5]
user_info: dict[str, str] = {"name": "太郎", "email": "taro@example.com"}
coordinates: tuple[float, float] = (35.6895, 139.6917)
また、Python 3.10からはUnion型の代わりにパイプ記号(|)が使えるようになりました:
# Python 3.10以降
id_or_name: int | str = "user123" # Union[int, str]と同等
maybe_name: str | None = None # Optional[str]と同等
型エイリアスの定義
複雑な型ヒントを何度も書くのは面倒ですよね。そんなときは型エイリアスを使いましょう。
from typing import Dict, List, Tuple, TypeAlias
# 型エイリアスの定義
UserId = int
UserName = str
Email = str
# より複雑な型のエイリアス
UserDict = Dict[UserId, Tuple[UserName, Email]]
# Python 3.10以降ではTypeAliasを使った明示的な型エイリアス定義も可能
Coordinates: TypeAlias = tuple[float, float]
# 使用例
users: UserDict = {
1: ("田中太郎", "taro@example.com"),
2: ("佐藤花子", "hanako@example.com")
}
location: Coordinates = (35.6895, 139.6917)
型エイリアスを使うと、コードの可読性が向上し、型の定義を一箇所にまとめられるので、変更が必要になった場合も修正が容易になります。
ジェネリック型の使い方
自分で定義したクラスでジェネリック型を使いたい場合は、Genericクラスを継承します。
from typing import Generic, TypeVar, List
# 型変数の定義
T = TypeVar('T')
K = TypeVar('K')
V = TypeVar('V')
# ジェネリッククラスの定義
class Box(Generic[T]):
def __init__(self, item: T) -> None:
self.item = item
def get_item(self) -> T:
return self.item
def set_item(self, item: T) -> None:
self.item = item
# 使用例
int_box: Box[int] = Box(42)
str_box: Box[str] = Box("こんにちは")
# 型変数に制約を付ける
S = TypeVar('S', str, bytes) # SはstrかbytesのみOK
def process_text(text: S) -> S:
# 処理...
return text
# 境界型変数(特定のクラスのサブクラスに制限)
class Animal:
def make_sound(self) -> str:
return "..."
class Dog(Animal):
def make_sound(self) -> str:
return "ワン!"
A = TypeVar('A', bound=Animal) # Animalまたはそのサブクラスのみ
def get_sound(animal: A) -> str:
return animal.make_sound()
ジェネリック型を使うと、型安全性を保ちながら柔軟なコードを書けます。特に、コレクションや汎用的なデータ構造を扱う場合に便利です。
Protocolクラスの活用
Pythonでは「ダックタイピング」という考え方が重要です。「アヒルのように歩き、アヒルのように鳴くなら、それはアヒルである」という原則です。
typing.Protocolを使うと、このダックタイピングを型ヒントで表現できます。
from typing import Protocol, List
# Protocolの定義
class Drawable(Protocol):
def draw(self) -> None:
... # 実装は必要なし、メソッドのシグネチャだけ定義
# Protocolを実装するクラス(明示的な継承は不要)
class Circle:
def __init__(self, radius: float) -> None:
self.radius = radius
def draw(self) -> None:
print(f"○ (半径: {self.radius})")
class Rectangle:
def __init__(self, width: float, height: float) -> None:
self.width = width
self.height = height
def draw(self) -> None:
print(f"□ (幅: {self.width}, 高さ: {self.height})")
# Protocolを使った関数
def draw_shapes(shapes: List[Drawable]) -> None:
for shape in shapes:
shape.draw()
# 使用例
shapes = [Circle(5.0), Rectangle(4.0, 3.0)]
draw_shapes(shapes) # 型チェックOK
Protocolを使うと、クラス間の明示的な継承関係がなくても、同じインターフェースを持つクラスを型安全に扱えます。これはPythonの柔軟性を損なわずに型チェックの恩恵を受けられる素晴らしい機能です。
型チェッカーの使い方
型ヒントを書いても、Pythonのインタプリタはそれを無視します。型チェックを行うには、外部ツールを使う必要があります。最も一般的なのはmypyです。
# mypyのインストール
pip install mypy
# 型チェックの実行
mypy your_script.py
例えば、以下のようなコードがあるとします:
# example.py
def add(a: int, b: int) -> int:
return a + b
result = add("hello", "world") # 型エラー
mypyで型チェックすると:
$ mypy example.py
example.py:4: error: Argument 1 to "add" has incompatible type "str"; expected "int"
example.py:4: error: Argument 2 to "add" has incompatible type "str"; expected "int"
このように、実行前に型の不一致を検出できます。
VSCodeやPyCharmなどのIDEを使っている場合は、エディタ上で直接型エラーを表示してくれるので、より効率的に開発できます。
実際のユースケース
実際のプロジェクトでのtypingモジュールの活用例を見てみましょう。
1. WebアプリケーションのAPI関数
from typing import Dict, List, Optional, TypedDict, Any
from datetime import datetime
# TypedDictを使った辞書の型定義
class UserData(TypedDict):
id: int
name: str
email: str
created_at: datetime
is_active: bool
profile: Optional[Dict[str, Any]]
def get_user(user_id: int) -> Optional[UserData]:
# データベースからユーザー情報を取得する処理
# 存在しない場合はNoneを返す
...
def get_active_users() -> List[UserData]:
# アクティブなユーザーのリストを返す処理
...
def create_user(name: str, email: str, profile: Optional[Dict[str, Any]] = None) -> UserData:
# 新しいユーザーを作成する処理
...
2. データ処理パイプライン
from typing import Callable, Iterator, List, TypeVar, Generic
T = TypeVar('T')
U = TypeVar('U')
class Pipeline(Generic[T, U]):
def __init__(self, processor: Callable[[T], U]) -> None:
self.processor = processor
self.next_pipeline: Optional[Pipeline[U, Any]] = None
def add_step(self, processor: Callable[[U], V]) -> 'Pipeline[T, V]':
self.next_pipeline = Pipeline(processor)
return self.next_pipeline
def process(self, data: T) -> U:
result = self.processor(data)
if self.next_pipeline:
return self.next_pipeline.process(result)
return result
# 使用例
def parse_data(raw_data: str) -> List[str]:
return raw_data.split(',')
def filter_data(data: List[str]) -> List[str]:
return [item for item in data if item.strip()]
def transform_data(data: List[str]) -> Dict[str, int]:
return {item: len(item) for item in data}
# パイプラインの構築
pipeline = Pipeline(parse_data)
pipeline.add_step(filter_data)
pipeline.add_step(transform_data)
# データ処理
result = pipeline.process("a,b,,c,d")
print(result) # {'a': 1, 'b': 1, 'c': 1, 'd': 1}
注意点と落とし穴
typingモジュールを使う際の注意点をいくつか紹介します。
1. 循環インポートの問題
型ヒントで別モジュールのクラスを参照すると、循環インポートが発生することがあります。その場合は文字列リテラルを使います。
# user.py
from typing import List, Optional
from post import Post # 循環インポートの可能性
class User:
def __init__(self, name: str) -> None:
self.name = name
self.posts: List['Post'] = [] # 文字列リテラルを使用
# post.py
from typing import Optional
from user import User # 循環インポート
class Post:
def __init__(self, title: str, author: 'User') -> None: # 文字列リテラルを使用
self.title = title
self.author = author
Python 3.7以降では、from __future__ import annotationsを使うことで、すべての型アノテーションを文字列として扱うこともできます。
from __future__ import annotations
from typing import List
class Node:
def __init__(self) -> None:
self.children: List[Node] = [] # 循環参照でもOK
2. 実行時の型チェックは行われない
型ヒントはあくまでヒントであり、実行時には無視されます。実行時に型チェックを行いたい場合は、自分で実装する必要があります。
def add(a: int, b: int) -> int:
if not isinstance(a, int) or not isinstance(b, int):
raise TypeError("引数はint型である必要があります")
return a + b
3. Any型の過剰使用
Any型は任意の型を表し、型チェックを事実上無効にします。便利ですが、過剰に使うと型ヒントの恩恵が失われます。
from typing import Any, Dict
# 避けるべき例
def process_data(data: Any) -> Any:
return data
# 改善例
def process_data(data: Dict[str, int]) -> List[str]:
return [f"{k}: {v}" for k, v in data.items()]
4. Python 3.5と3.6の型ヒントの違い
Python 3.5と3.6では、変数の型ヒントの書き方が異なります。
# Python 3.5
from typing import Dict, List
users = [] # type: List[str]
config = {} # type: Dict[str, int]
# Python 3.6以降
users: List[str] = []
config: Dict[str, int] = {}
5. TypedDictの部分的な更新
TypedDictは便利ですが、部分的な更新が型チェック上難しいという問題があります。
from typing import TypedDict, NotRequired
# Python 3.11以降ではNotRequiredが使える
class UserProfile(TypedDict):
name: str
age: int
bio: NotRequired[str] # 省略可能なフィールド
# 部分的な更新(型チェッカーはエラーを出す可能性あり)
def update_user(user_id: int, data: dict) -> None:
# ...
まとめ
Pythonのtypingモジュールは、動的型付け言語であるPythonに静的型チェックの恩恵をもたらす強力なツールです。
- 基本的な型ヒント(
str、int、floatなど) - 複合型(
List、Dict、Tuple、Setなど) - 特殊な型(
Optional、Union、Anyなど) - 型エイリアスによる型定義の再利用
- ジェネリック型による型安全な汎用コード
Protocolによるダックタイピングの型付けmypyなどの型チェッカーによる静的解析
型ヒントを活用することで、コードの可読性が向上し、バグの早期発見が可能になります。また、IDEの補完機能も強化されるため、開発効率も上がります。
Pythonの型ヒントは、静的型付け言語の厳格さと動的型付け言語の柔軟性のバランスを取った素晴らしい機能です。ぜひ、あなたのプロジェクトに取り入れてみてください!
おしまい
わぁ、typingモジュールってこんなに便利なんだね!特にProtocolの考え方は、Pythonらしい柔軟さを残しながら型安全性を高められるって素敵だね。
そうだね!最初は型ヒントを書くのが少し面倒に感じるかもしれないけど、大きなプロジェクトになればなるほど、その価値は高まるよ。バグの早期発見や、コードの自己文書化、リファクタリングの安全性向上など、メリットは計り知れないんだ。
早速、自分のプロジェクトに取り入れてみるね!ありがとう、ペンギンさん!
いつでも質問してね!Pythonの型ヒントの世界を楽しんでくれたら嬉しいよ!
・・・
冒頭と結びの会話は直したいな。
まとめ
Clineはやっぱりスゴイ。
おしまい
こんなに書けてしまった・・・
これでやりたいことに注力出来るな。
以上になります!


コメント