
はじまり
今年もアレの季節だな・・・
アレだね
しかも昨年はアレをしたからな・・・
アレをしたね
為替差益の計算を自動化したい
昨年、円安前から貯め続けていた外貨を円に換えてしまいました・・・。
確定申告の際、為替取引による利益(為替差益)を計算する必要がありますが、取引履歴のPDFから必要なデータを手作業で抽出するのは時間がかかり、ミスも起こりやすいものです。
そこで今回は、Google Cloud の Document AI を使って、PDFからOCRで自動的にデータを抽出し、為替差益を計算する方法を紹介します。
Document AIとは?
Document AIは、GoogleのCloud AI/MLサービスの1つで、PDFや画像から構造化されたデータを抽出できるサービスです。一般的なOCRとは異なり、以下のような特徴があります:
- 高度なデータ抽出
- 単なるテキスト認識だけでなく、表形式データの認識が可能
- フォームからの特定フィールドの抽出
- 請求書、領収書、契約書などの定型文書の処理
- カスタマイズ可能
- カスタムプロセッサによる特定データの抽出
- 独自のトレーニングデータによる精度向上
- 多言語対応
- 実用的な機能
- 自動レイアウト分析
- エンティティ抽出
- テーブル構造の認識
Document AIは以下のような場面で特に威力を発揮します:
- 請求書処理の自動化
- 契約書からの重要情報抽出
- 金融取引データの分析
- 医療記録のデジタル化
今回は、この強力なツールを使って確定申告のための為替取引データ抽出を自動化してみましょう。
実装手順
以下の流れで、為替差益の計算まで完了させたいと思います。
- 各証券口座から取引履歴PDFを収集する。
- 取引履歴PDFの前処理をする。
- Document AIをセットアップする。
- カスタムプロセッサの作成およびカスタムプロセッサに学習させる。
- Pythonでカスタムプロセッサを使う機能を実装する。
- 為替差益を計算する。(今回は総平均法を使います。)
各証券口座から取引履歴PDFを収集する。
まず、為替差益が発生した各証券口座から、その為替取引に関わる取引履歴を扱ったPDF文書を収集します。
これは各証券口座にログインして口座管理画面などからアクセスして集められるので操作としては単純ですが・・・。
何せ収集量が多い。
僕が昨年に発生させた為替差益は1箇所の証券口座のみでしたが、それでも4年分の外国証券の取引履歴、配当金に関する書類などを集める必要があったので、この作業だけでも2時間ぐらい掛かりました・・・。
取引履歴PDFの前処理をする。
そしたら、PDFから必要なデータを抽出しやすくするための前処理を行います。
- PDFの表示縮尺を調整してスクリーンショットを撮影する。
- 個人情報を省くためにトリミングする。
スクショのトリミングには、以前にPowerShellで実装したものを使います。実装した時の記事は以下にありますのでご参考程度に。

PowerShellにおけるトリミングの処理とは、簡潔に書くとざっと以下のようなイメージです。
# PowerShellでトリミング処理を自動化
function Trim-Image {
param(
[string]$inputPath,
[string]$outputPath,
[int]$x,
[int]$y,
[int]$width,
[int]$height
)
Add-Type -AssemblyName System.Drawing
$image = [System.Drawing.Image]::FromFile($inputPath)
$bitmap = New-Object System.Drawing.Bitmap($width, $height)
$graphics = [System.Drawing.Graphics]::FromImage($bitmap)
$graphics.DrawImage($image,
(New-Object System.Drawing.Rectangle(0, 0, $width, $height)),
(New-Object System.Drawing.Rectangle($x, $y, $width, $height)),
[System.Drawing.GraphicsUnit]::Pixel)
$bitmap.Save($outputPath)
$graphics.Dispose()
$bitmap.Dispose()
$image.Dispose()
}
そんな感じの処理を実行して、以下のようなPNG画像を何枚か作ります。以下はDocument AIを使っている時のスクショです。
Document AIのセットアップと学習
まず、Google Cloud Consoleで新しいプロジェクトを作成し、Document AI APIを有効化します。
# Google Cloud CLIでプロジェクトを設定
gcloud config set project your-project-id
# Document AI APIを有効化
gcloud services enable documentai.googleapis.com
以下の流れでDocument AIでカスタムプロセッサを作成していきます。各手順の詳細は後ほど記載していきます。
- カスタムプロセッサを作成する。
- トレーニングを開始します。ラベリングをしてスキーマを定義します。
- 「ビルド」>「基盤モデルを呼び出す」を選択して、トレーニングさせるベースモデルを選びます。
- 「新しいバージョンを作成」で、学習させたモデルにバージョン名を設定してビルドする。
- ビルド完了後、そのモデルをデプロイしてデフォルトのバージョンに設定する。
以下、Document AIをWebコンソール上で利用した際に感じた留意点です。
- Document AIのUXは少し分かりづらいです
- デプロイ状態の確認が不明確な場合があります
- 「1個のバージョンをデプロイしています。」というメッセージが表示されても、実際には使用可能な状態かもしれません
カスタムプロセッサを作成する。
Document AI Workbenchに移動して、カスタムプロセッサを作成します。
以下の項目をDocument AI上で入力します。
- プロセッサ名:「test_extractor」
- 目的:取引履歴からの自動データ抽出
トレーニングを開始。ラベリングをする。
そしたら早速トレーニングを開始します。
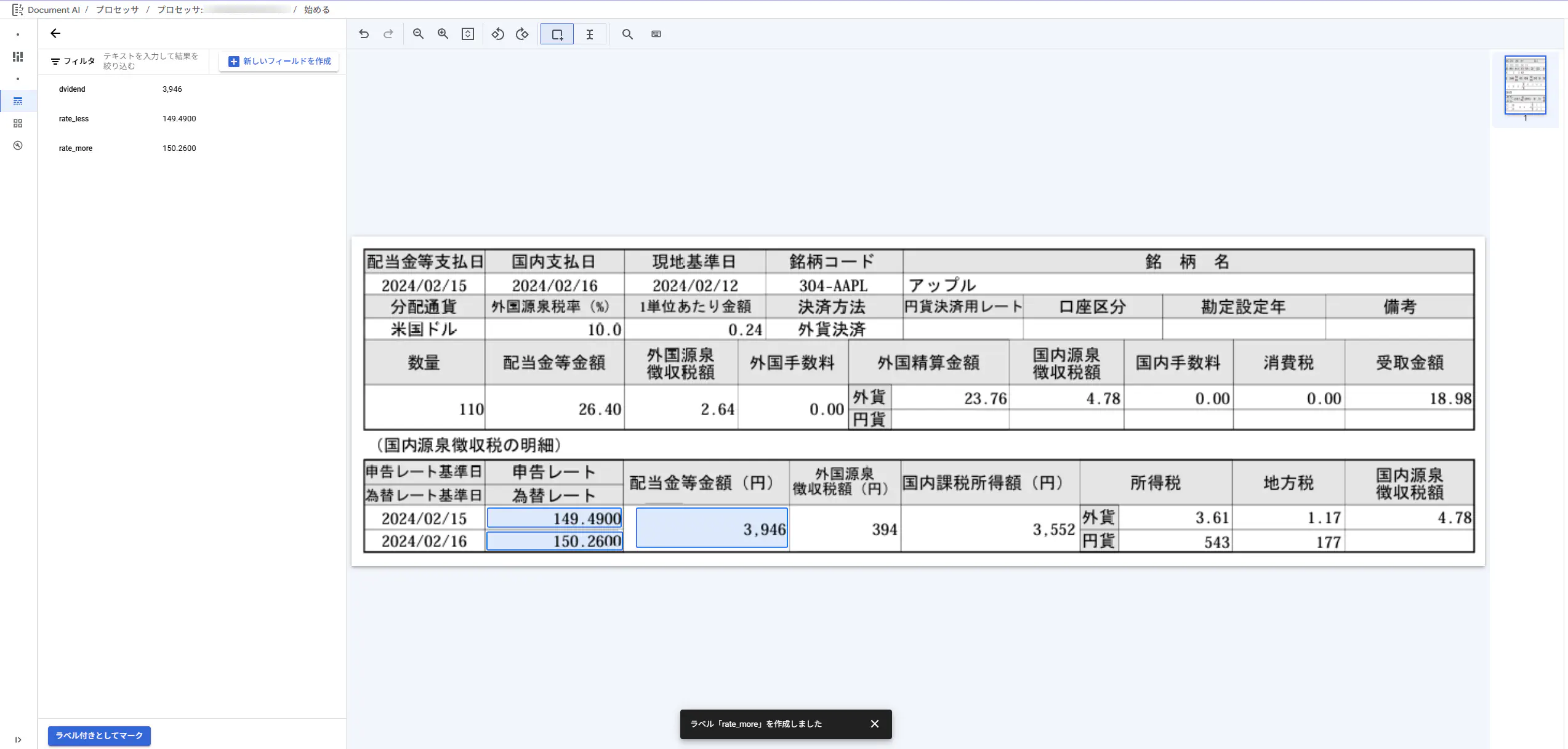
以下のようコンソール内のGUI上で、PNG画像の中でOCRさせたい箇所を選んでラベリングして、スキーマを定義していきます。
証券銘柄のシンボルは、学習元のAIが自動的にラベリングしてくれました。元々の能力が高いですね。
一旦これで1枚目のラベリングは完了しました。
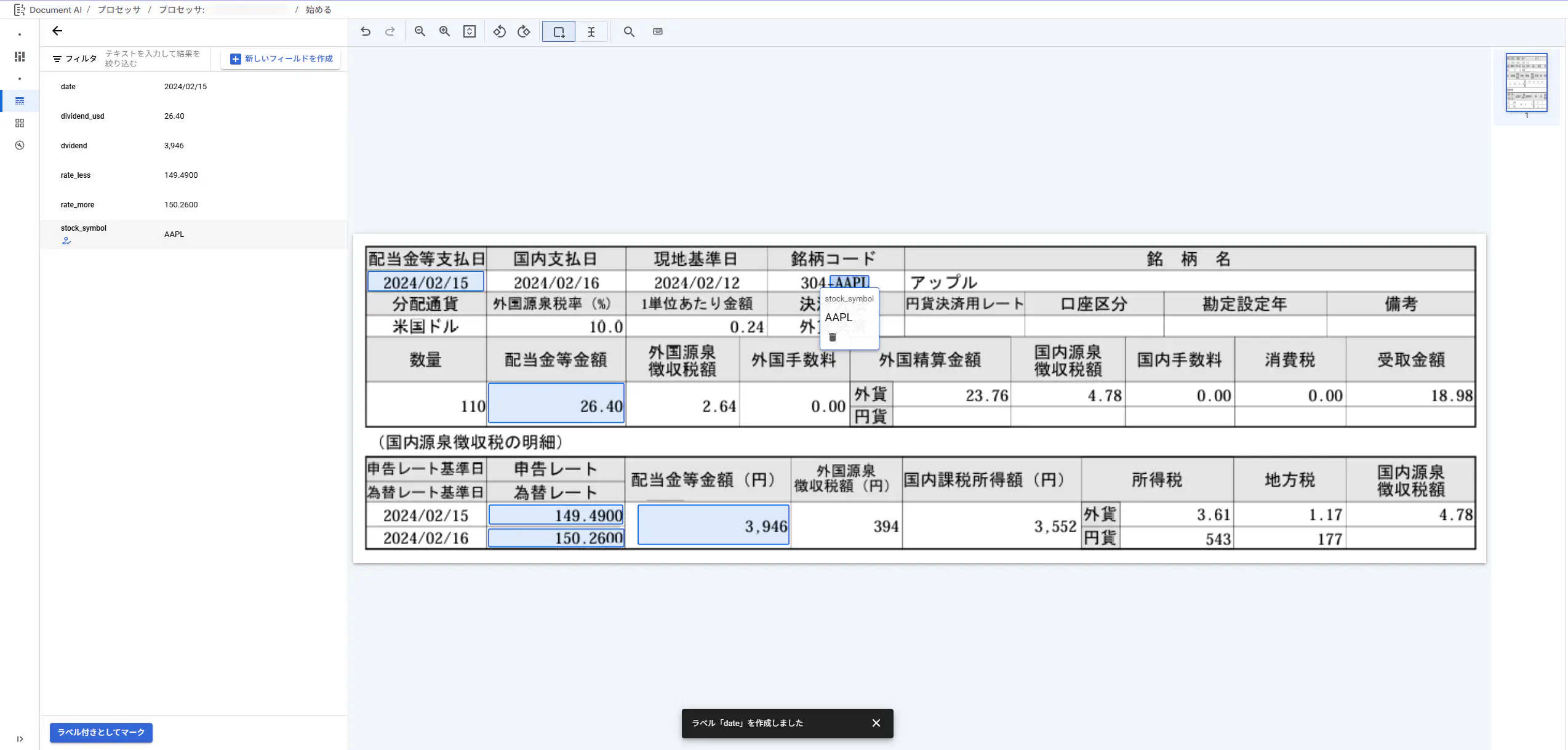
2枚目からはラベリングした情報を元に、モデルが自動的にラベリングしてくれるようになります。その自動ラベリング結果を承認するかどうかはユーザ次第。
しかしながら、殆ど当たっていますね。これは少ない学習量で済みそう。5枚も要らなさそう。
「ビルド」>「基盤モデルを呼び出す」
ラベリングが終わったら、次に学習させるAIモデルを選んでいきます。
AIモデルは「基盤モデルを呼び出す」、「ファインチューニング」、「カスタムモデルのトレーニング」から選べますが、今回のような比較的単純なドキュメントを読み取る場合は、「基盤モデルを呼び出す」を選択すれば、トレーニングに必要なデータセットが少なく済みます。
今回は、「基盤を呼び出す」で作っていきます。
「新しいバージョンを作成」で学習させたモデルにバージョン名を設定してビルドする。
適当にバージョン名を付けて、先ほどラベリングしたデータを選択したAIモデルに学習させて、そのモデルをビルドします。
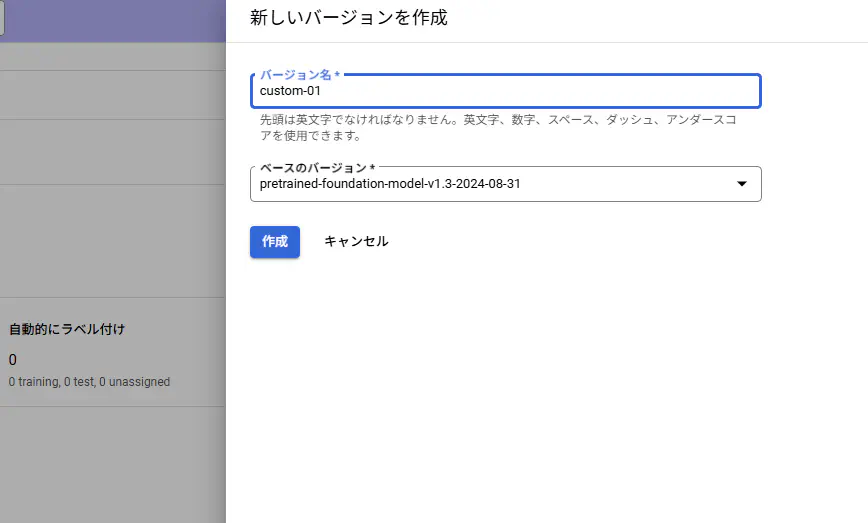
学習させたモデルをデプロイする。
ビルドが終わったら、「テストと評価」の項目に移ります。
しかし、「テストと評価」の作業を行うためには、その前に「デプロイと使用」を行わなければならないようです。(なんで工程の順番が逆なの?)
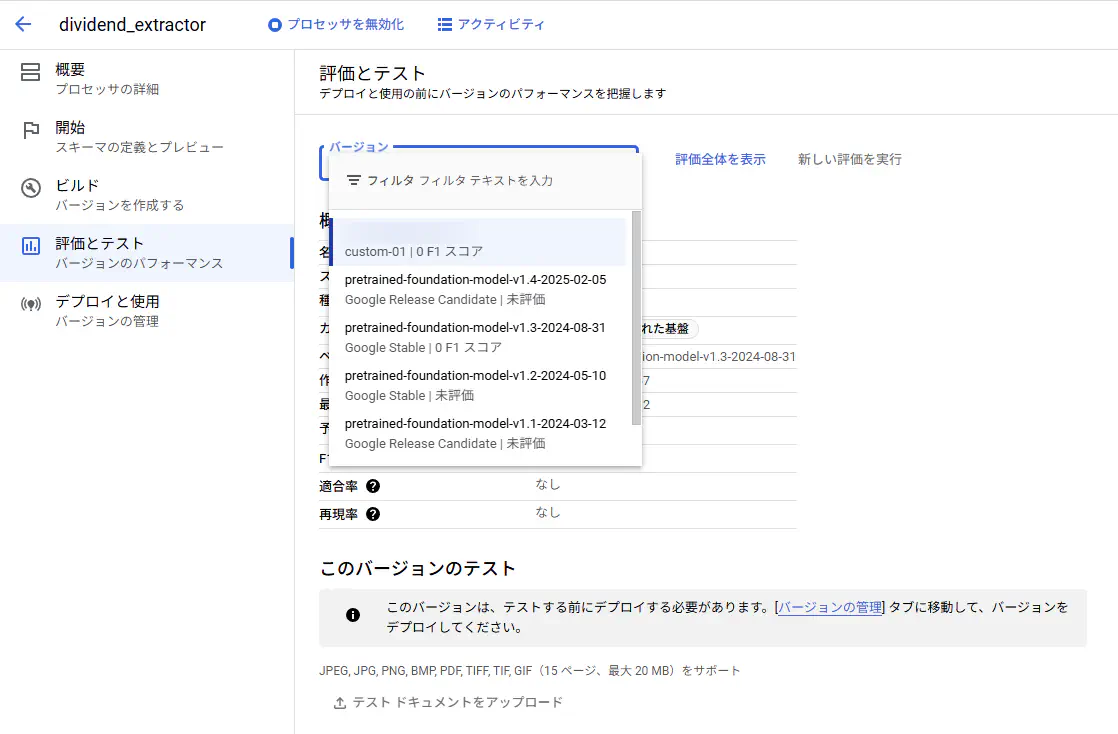
それでは、「デプロイと使用」で先ほどビルドしたバージョンを選択してデプロイします。バージョンを選択したらデプロイすることが出来ます。
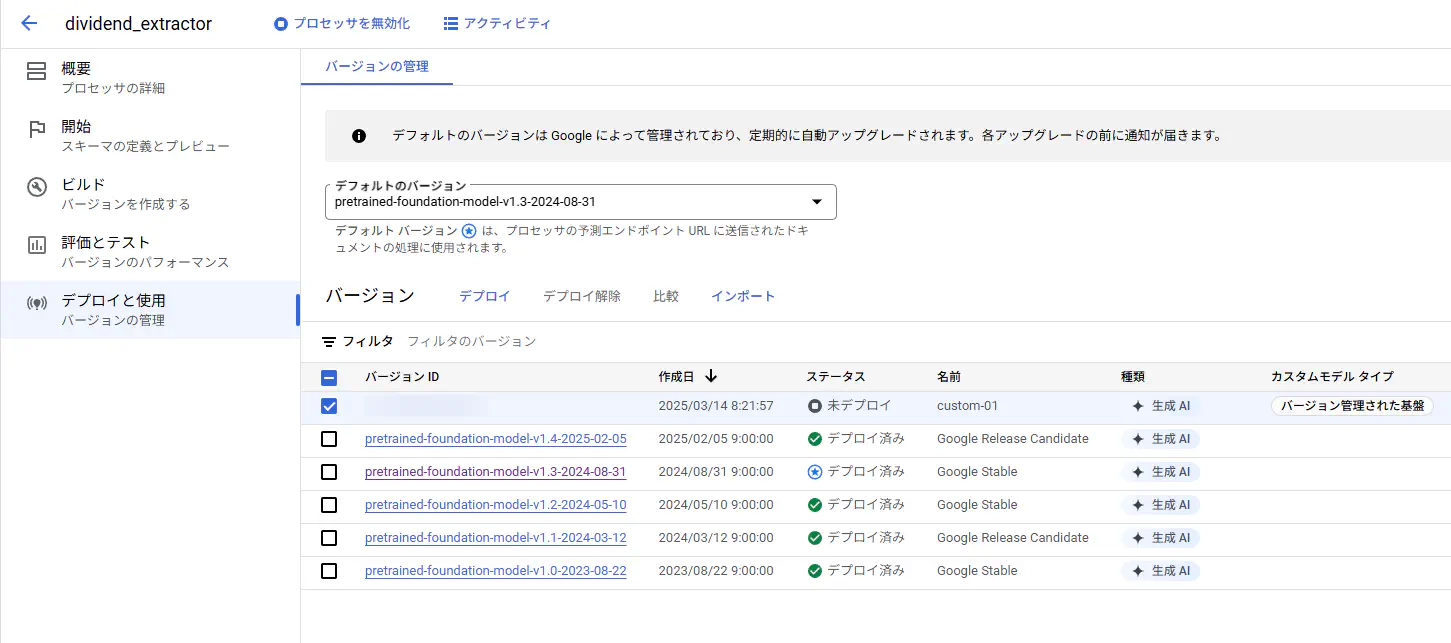
デプロイが始まりました・・・。画面下の方に「1個のバージョンをデプロイしています。」といったメッセージが表示されて、何十分経っても表示されたままでしたが、とりあえずそのトレーニングさせたバージョンをデフォルトに設定して、実際にローカルから使っていきました。
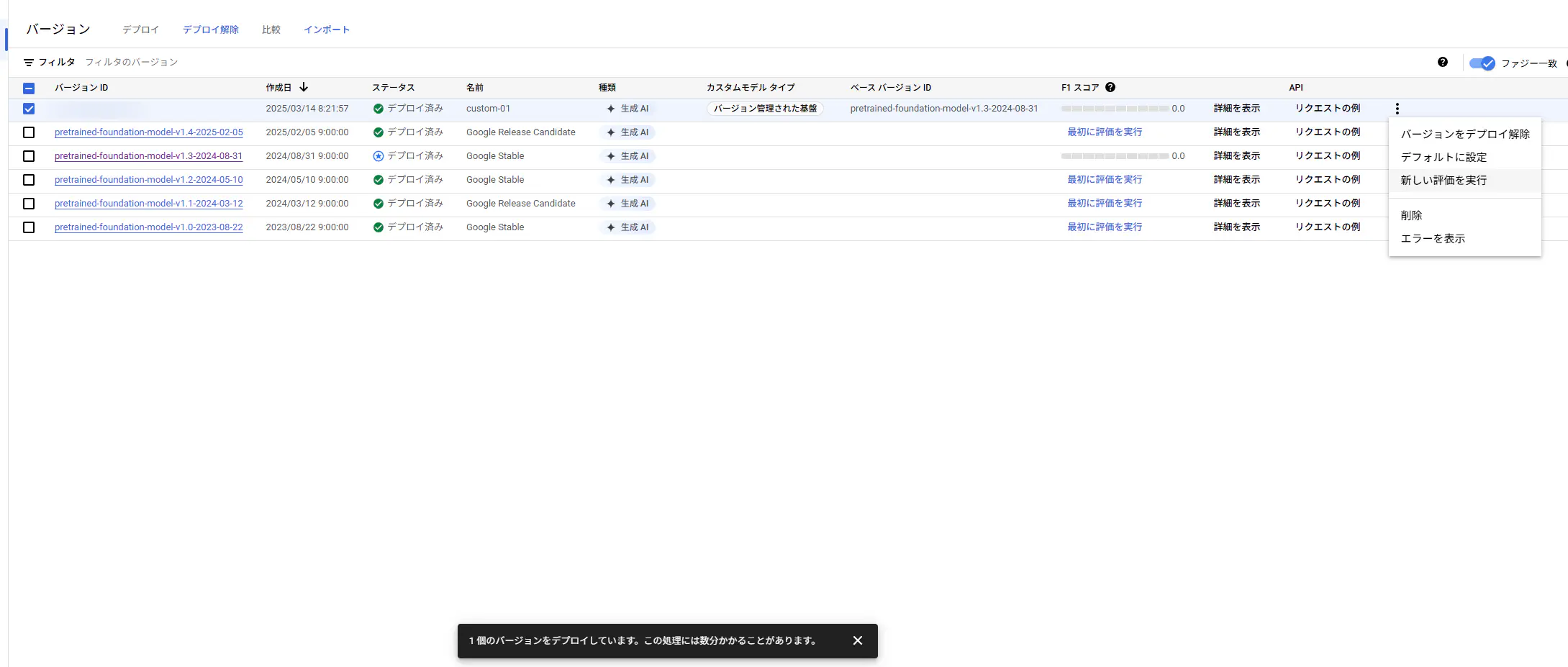
これで、Document AI内での作業は完了です。
Pythonでの実装
次に、先ほど作成したカスタムプロセッサを使って、ローカルに置いてある資料をOCRさせていきます。今回はPythonとColab Notebookを使いました。
公式サンプルコード
GitHubにて公開されていたGoogle公式サンプルコードを参考に実装します:
# [START documentai_process_document]
from typing import Optional
from google.api_core.client_options import ClientOptions
from google.cloud import documentai # type: ignore
# TODO(developer): Uncomment these variables before running the sample.
# project_id = "YOUR_PROJECT_ID"
# location = "YOUR_PROCESSOR_LOCATION" # Format is "us" or "eu"
# processor_id = "YOUR_PROCESSOR_ID" # Create processor before running sample
# file_path = "/path/to/local/pdf"
# mime_type = "application/pdf" # Refer to <https://cloud.google.com/document-ai/docs/file-types> for supported file types
# field_mask = "text,entities,pages.pageNumber" # Optional. The fields to return in the Document object.
# processor_version_id = "YOUR_PROCESSOR_VERSION_ID" # Optional. Processor version to use
def process_document_sample(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
field_mask: Optional[str] = None,
processor_version_id: Optional[str] = None,
) -> None:
# You must set the `api_endpoint` if you use a location other than "us".
opts = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
client = documentai.DocumentProcessorServiceClient(client_options=opts)
if processor_version_id:
# The full resource name of the processor version, e.g.:
# `projects/{project_id}/locations/{location}/processors/{processor_id}/processorVersions/{processor_version_id}`
name = client.processor_version_path(
project_id, location, processor_id, processor_version_id
)
else:
# The full resource name of the processor, e.g.:
# `projects/{project_id}/locations/{location}/processors/{processor_id}`
name = client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load binary data
raw_document = documentai.RawDocument(content=image_content, mime_type=mime_type)
# For more information: <https://cloud.google.com/document-ai/docs/reference/rest/v1/ProcessOptions>
# Optional: Additional configurations for processing.
process_options = documentai.ProcessOptions(
# Process only specific pages
individual_page_selector=documentai.ProcessOptions.IndividualPageSelector(
pages=[1]
)
)
# Configure the process request
request = documentai.ProcessRequest(
name=name,
raw_document=raw_document,
field_mask=field_mask,
process_options=process_options,
)
result = client.process_document(request=request)
# For a full list of `Document` object attributes, reference this page:
# <https://cloud.google.com/document-ai/docs/reference/rest/v1/Document>
document = result.document
# Read the text recognition output from the processor
print("The document contains the following text:")
print(document.text)
# [END documentai_process_document]
process_document_sample(
project_id="000000000000",
location="us",
processor_id="xxxxxxxxxxxxxx ",
file_path = "/content/drive/MyDrive/TemporarySave/ImagesForAgentWorking/スクリーンショット 2025-03-14 072159.png",
mime_type="image/png",
)
Colab Notebook上で、Python実行前に必要かもしれない処理。
!gcloud auth application-default login
!gcloud auth application-default set-quota-project [project-id]
!pip install --upgrade google-genai
!pip install google-cloud-documentai==3.0.1
以下のように、Googleドライブに資料を格納して、Colab Notebookにドライブをマウントします。
The document contains the following text:
Document Al / プロセッサ / プロセッサ: xxxxxxxxxxxxxx / 始める
←
!i!
=フィルタ
テキストを入力して結果を
絞り込む
+ 新しいフィールドを作成
dvidend
3,946
rate_less
149.4900
rate_more
150.2600
ラベル付きとしてマーク
I>
52
Q
(国内源泉徴収税の明細)
配当金等支払日
国内支払日
現地基準日
銘柄コード
銘
柄名
2024/02/15
2024/02/16
2024/02/12
304-AAPL
アップル
分配通貨
外国源泉税率(%)
1単位あたり金額
決済方法
円貨決済用レート
口座区分
勘定設定年
備考
米国ドル
10.0
0.24
外貨決済
数量
配当金等金額
外国源泉
徴収税額
外国手数料
外国精算金額
国内源泉
徴収税額
国内手数料
消費税
受取金額
外貨
23.76
4.78
0.00
0.00
18.98
110
26.40
2.64
0.00
円貨
ラベル 「rate_more」を作成しました
X
申告レート基準日
為替レート基準日
申告レート
為替レート
配当金等金額(円)
外国源泉
徴収税額(円)
国内課税所得額(円)
所得税
地方税
国内源泉
徴収税額
2024/02/15
149.4900
外貨
3.61
1.17
4.78
2024/02/16
150.2600
3,946
394
3,552
円貨
543
177
取得できたデータをCSV形式などで出力して、スプレッドシート上に反映すれば、外国証券の売買履歴および配当金の授受履歴のデータが格納された、為替取引の計算シートの完成です!
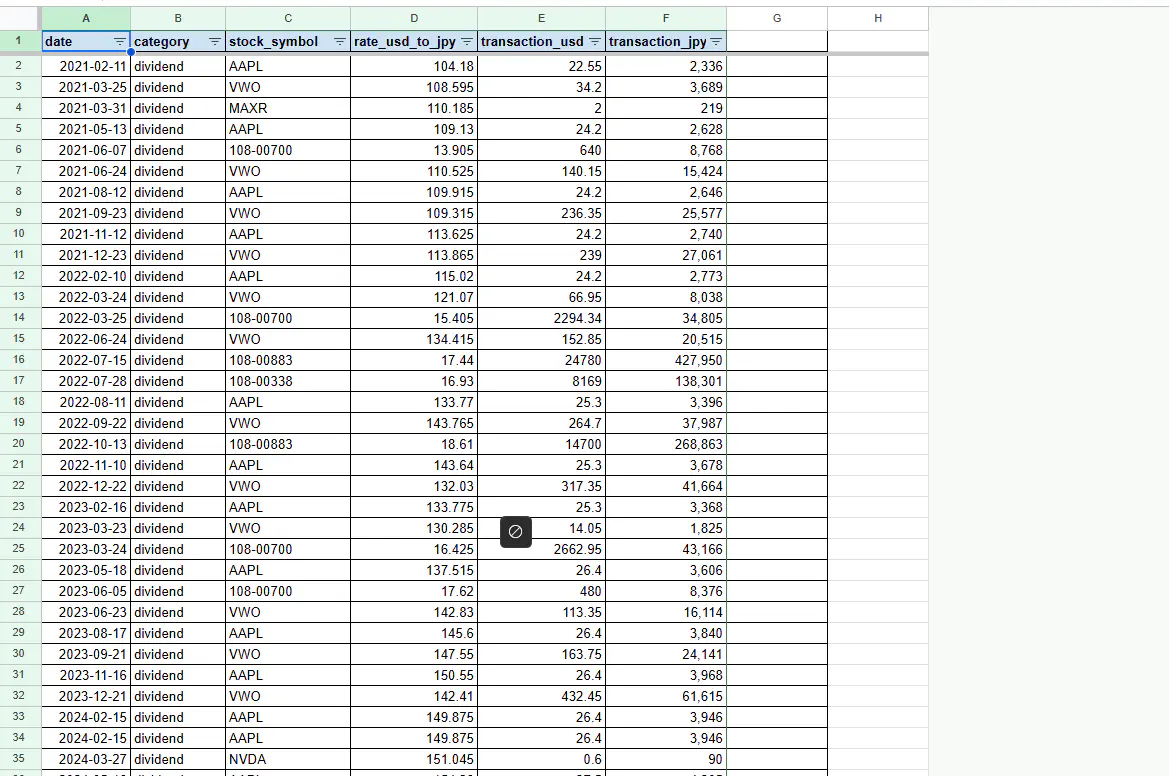
これらのデータを元に計算すれば、為替差益による利益を確定申告書に入力することが出来ますね!
【参考】Document AI APIからのレスポンスの仕様
Document AIでドキュメントを解析すると、ラベル付けした各項目は「エンティティ(entities)」として出力されます。(2025-03-26時点)つまり、データセットでラベル付けした部分の情報は、解析結果のJSONオブジェクト内のentities配列に格納されます。
エンティティの構造
各エンティティには以下のような情報が含まれます:
- type_(ラベルの種類) 例: 「請求書番号」「日付」「金額」など、あなたがラベル付けした名前が入ります。
- mention_text(抽出されたテキスト) 実際に読み取った文字列がここに格納されます。
- normalized_value(正規化された値) 日付や金額など、フォーマットが統一された値がある場合に利用できます。
- confidence(信頼度) 解析結果の精度を表す数値です。
- page_anchor ラベル付けしたテキストがどのページ、どの位置にあったかの情報です。
ラベル付け部分の値を取得する例(Python)
以下は、解析済みのDocumentオブジェクトから各エンティティを取得し、ラベルとその値を表示するサンプルコードです。
from google.cloud import documentai_v1 as documentai
# 例として、既にDocument AIで処理されたdocumentオブジェクトがあるとする
document = client.process_document(request=request).document
# エンティティごとにループし、ラベルと抽出された値を出力
for entity in document.entities:
print("ラベル:", entity.type_)
print("抽出値:", entity.mention_text)
# 正規化された値が存在する場合はそちらも利用可能
if entity.normalized_value:
print("正規化された値:", entity.normalized_value.text)
print("信頼度:", entity.confidence)
print("---")
このコードでは、document.entities に含まれる各エンティティから、ラベル(type_)、実際に読み取ったテキスト(mention_text)、および(存在すれば)正規化された値を取得しています。これにより、データセットでラベル付けした各部分の値をプログラム内で利用可能です。
カスタムプロセッサの場合
もしカスタムラベルや独自のアノテーションを使用している場合は、各エンティティのtype_にカスタムで設定したラベル名が入るため、目的に合わせて条件分岐などで抽出することも可能です。
為替差益の計算方法
今回は売却を任意の日で一括で行ったため、総平均法で計算しました。
売却を都度行っている場合は先入先出法の方がオトクかもしれませんね。
OCRに使ったコストと作業時間
今回、カスタムプロセッサを作るために使ったAPIコストに関しては、80枚の画像処理で872円の料金が掛かりました。
まあまあ掛かった気がしますが、次回の為替差益の計算が楽になったので特に問題なく感じています。
まとめ
今回はDocument AIを使って、確定申告のために必要なデータである為替差益に関する情報を、証券口座から受け取った書類からOCRして、スプレッドシートに一気に反映する方法を紹介しました。
以下が記事のまとめです。
- Document AIでは、5枚以下の学習データで、証券取引の書類からデータを抽出出来るAIモデルを構築出来る。
- Document AIでは、用途ごとにAIモデルを「基盤モデルを呼び出す」、「ファインチューニング」、「カスタムモデルのトレーニング」の中から選べる。
- PythonからDocument AIのモデルから情報を取得する際には、
document.entitiesに含まれる各エンティティから正規化された情報を取得出来る。 - コストは80枚で872円ぐらい掛かった。
おしまい
結構漏れないな!
一つ大きな作業が減ったぞ。
以上になります!


コメント