
はじまり
ああもう、いちいち認証画面出すのめんどくさいなあ・・・
ああ、ときどき表示されるやつだな
この記事の読者の想定
- Google CloudのDocumet AIを使ったことがない人
この記事で扱うこと
PCを買い替えたりした時に、ゲームも再びインストールし直すことになりますが、その際に以前に使用していたゲーム内の設定がデフォルトのものになっていることは、「あるある」な出来事だと思います。
僕も、「Satisfactory」というゲームをよく嗜むもので、沢山ある設定を再度設定し直すのは骨が折れます。
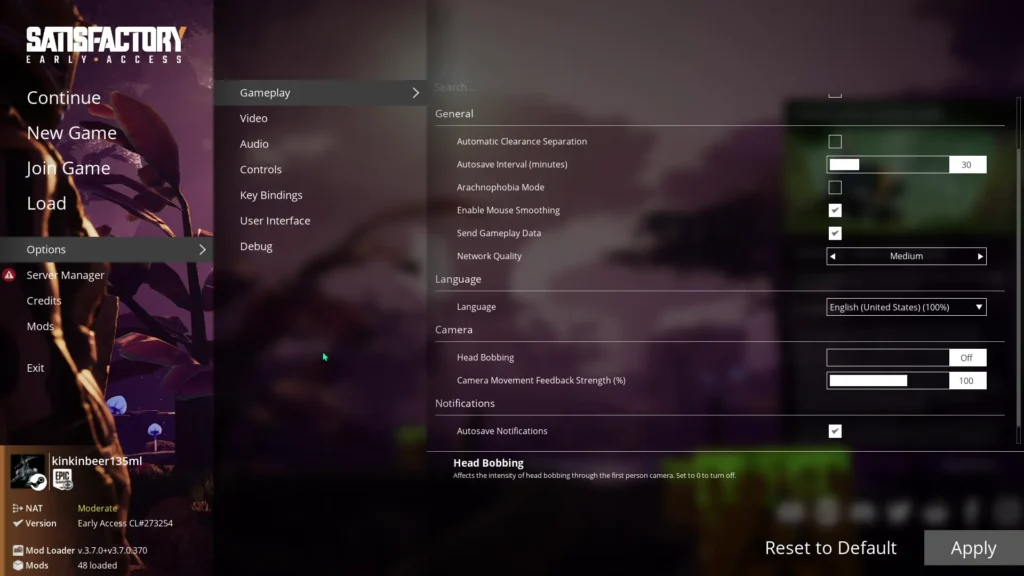
そこで、このゲームの設定を管理することで、再設定する作業を楽にしていこうかと思います。
上記のようにスクショしたファイルを、どこかのクラウドに上げるのが最も手っ取り早いです。そう思います。
しかし、今回の記事では、そのバックアップするファイルを文字列として管理したいので、テキストデータに変換するためにGoogle Cloud上で利用できるドキュメントOCR機能の一つである、「Document AI」を試していこうかと思います。
Document AIとは
Google CloudのDocument AIは、ドキュメント解析のための機械学習モデルを提供するサービスです。
このツールは、PDF、画像などのフォーマットのドキュメントからテキストやその他のデータを抽出することができます。
従来の光学式文字認識(OCR)に加えて、機械学習技術も利用されているので、以下のような事例に対して活用することが出来るみたいです。
- 請求書や領収書から、金額や日付、顧客情報などを自動的に抽出する
- 契約書から、当事者情報や契約条件などを自動的に抽出する
- アンケート用紙から、回答内容を自動的に集計する
- 名刺から、氏名や会社名、連絡先などを自動的に抽出する
果たしてゲーム設定画面を扱えるのだろうか
といったように、公共料金や日常生活でありがちなフォーマットで書かれている文書に対して利用できるツールを、「ゲームの設定画面」に対して適用させていこうと思います。
「ゲームの設定画面」も、書式的に画一されていると思うので、ある程度のデータセットがあれば学習できると思っています。
それでは行ってみましょう。
Document AIの最初の設定
まずは、Document AIがどのように操作していくものなのかを掴んでいこうと思います。
最初に、Google Cloudのコンソールを開いてプロジェクトを立ち上げたら、「Cloud Document AI API」を有効化します。
そうしたら、早速設定画面に触れていきます。
「Document AI を使ってみる」の直下にある「プロセッサを確認」をクリックします。
Document AIの標準のプロセッサ「Form Parser」を試す
クリックすると、色々な標準プロセッサが表示されます。
まずは、この中にあるものを使っていきます。おそらく「専用」プロセッサは公共料金やアンケート用紙のOCRに使用するもので使えるかどうか微妙だと思うので、今回はスルーします。
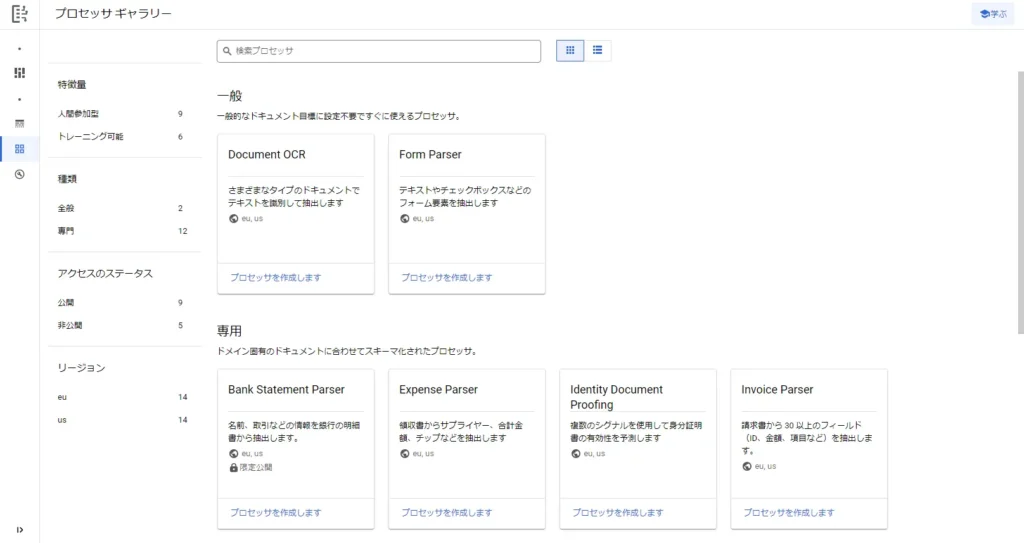
まず、フォームからキーと値で紐づけてくれそうな「Form Paser」というプロセッサを選択してみます。
プロセッサ名とリージョンを選択します。
そして、「暗号化」の部分は、Google Cloudの諸サービスでよく見る「Googleが管理する暗号鍵」にします。
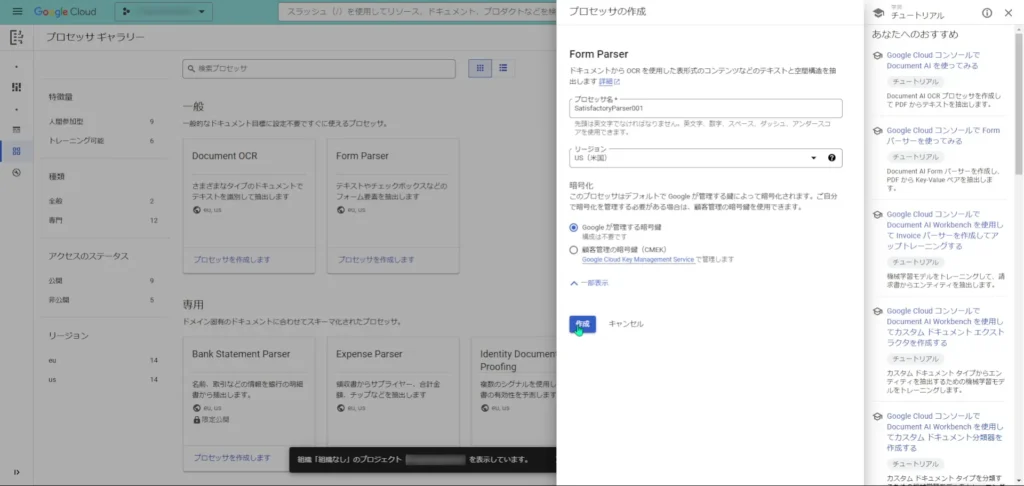
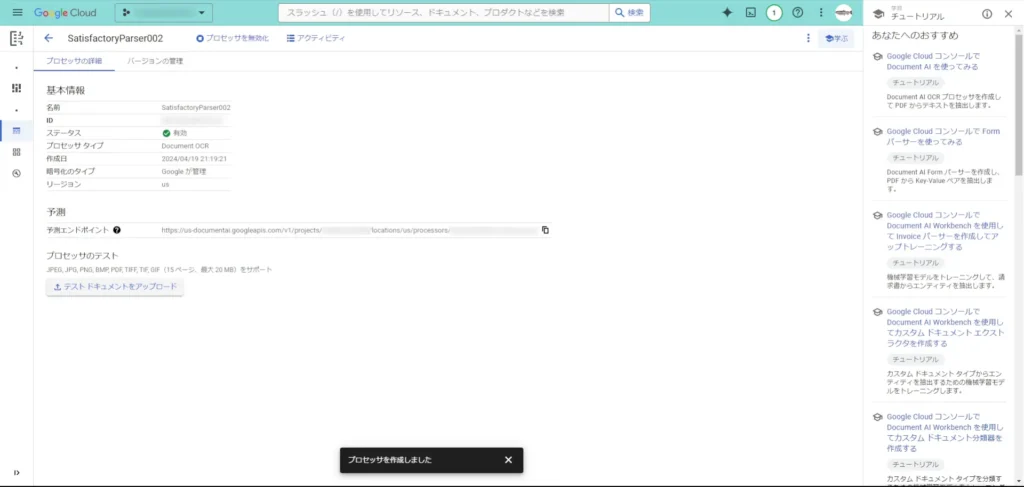
そうすると、プロセッサが作成されて、プロセッサのIDや予測エンドポイントが表示されます。
これらの情報は、このプロセッサにリクエストするまでは使いません。
それでは、「テストドキュメントをアップロード」をクリックして試してみましょう。
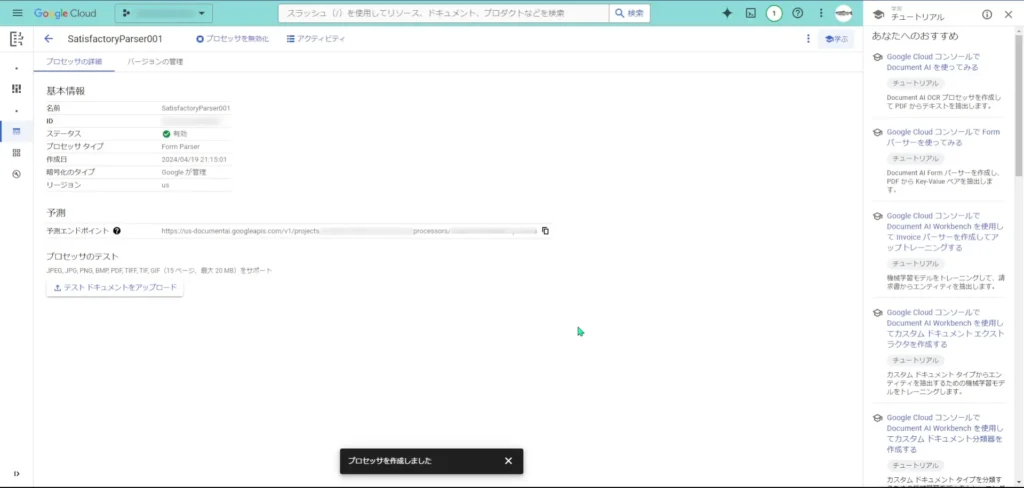
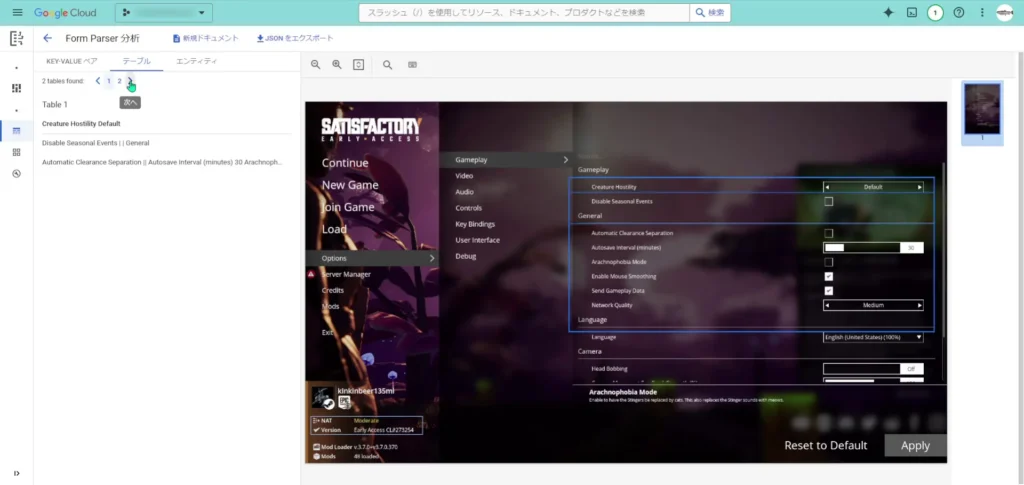
アップロードしてみると、「Form Parser」のOCRが実際にどの部分を検知したかどうかが表示されます。
まあ、そりゃ「New Game」などの設定とは関係ない文字が認識されるのはしょうがないと思います・・・
このプロセッサの状態ですと、目的の物を作るためには少し使えないですね。
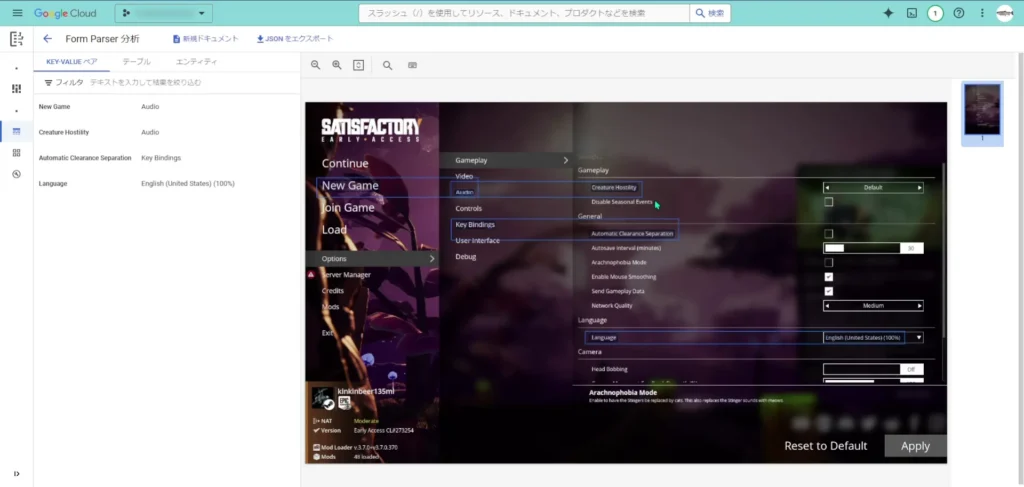
「KEY-VALUEペア」の中の1つをクリックすると、どの部分を指しているのかを確認することが出来ます。
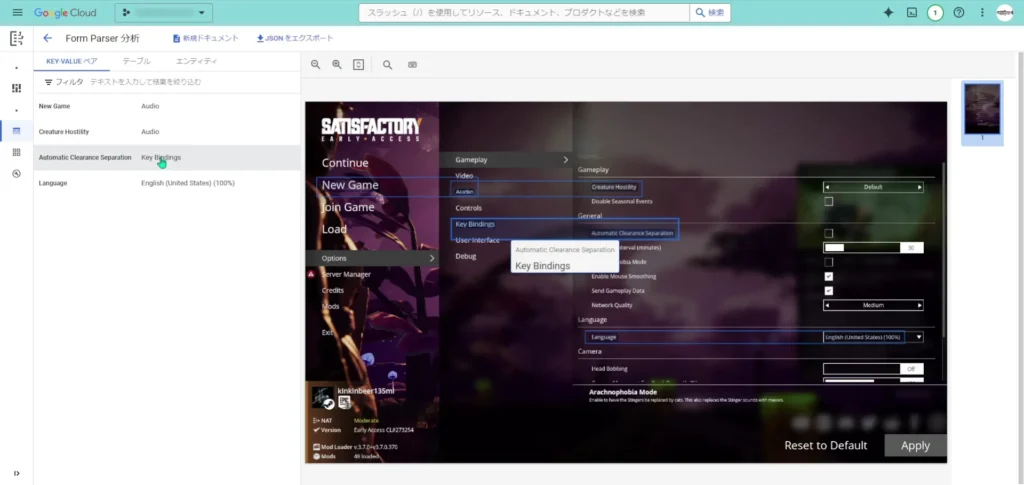
「テーブル」をクリックすると、テーブル状のフォームだと判断された部分が表示されます。
ここでも、あまりOCRでしっかり読み取れていませんね・・・
「エンティティ」は、該当すると判断された箇所がありませんでした。
Document AIの標準のプロセッサ「Document OCR」を試す
Form Parserでは厳しそうでしたので、もう一つの標準プロセッサである「Document OCR」を試していこうと思います。
「Form Parser」と同様に、プロセッサ名とリージョンと暗号化を設定していきます。
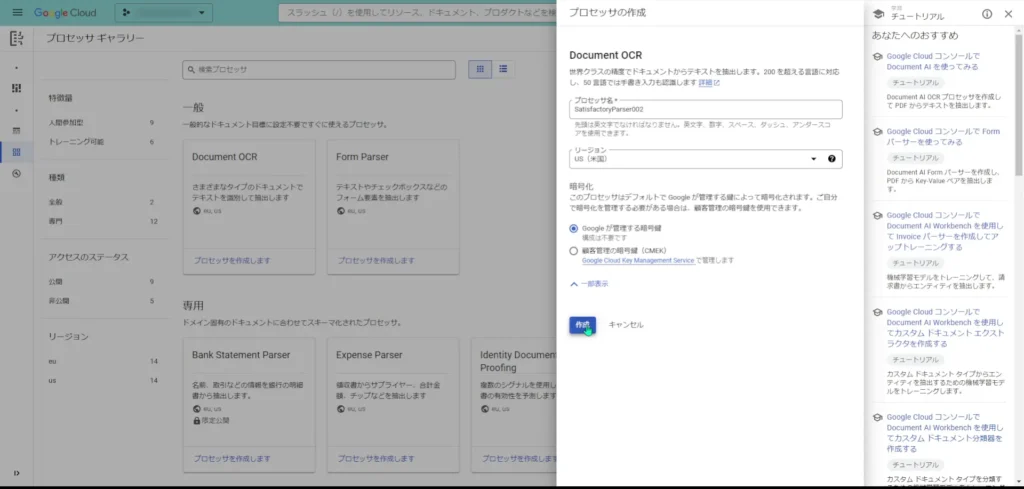
プロセッサが作成されると、Form Parserと同様の情報が表示されます。
「テストドキュメントをアップロード」をクリックしてOCRを試します。
アップロードしてOCRされた結果が表示されました。
しかし、やはりOCRはただ単に文字列を判別して網羅するだけですので、もう一声欲しいです。キーバリュー型で欲しいですね。
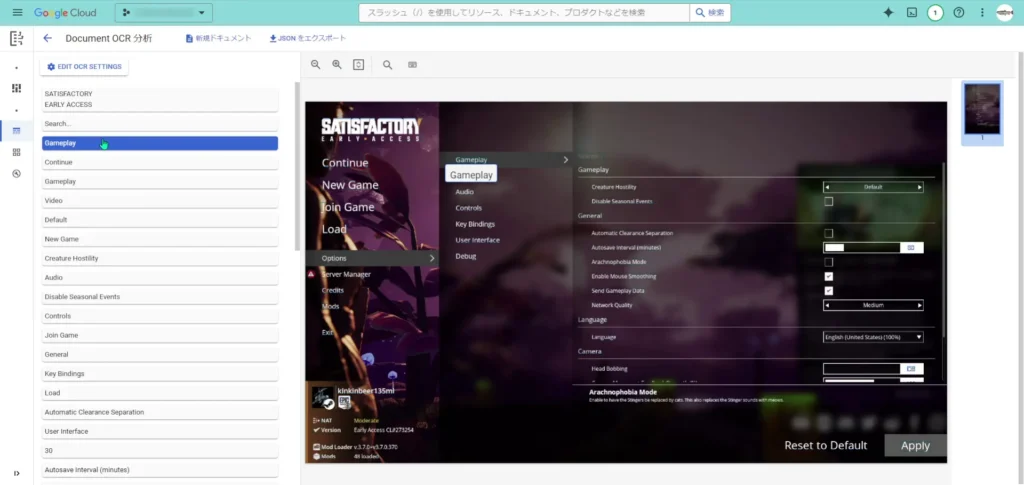
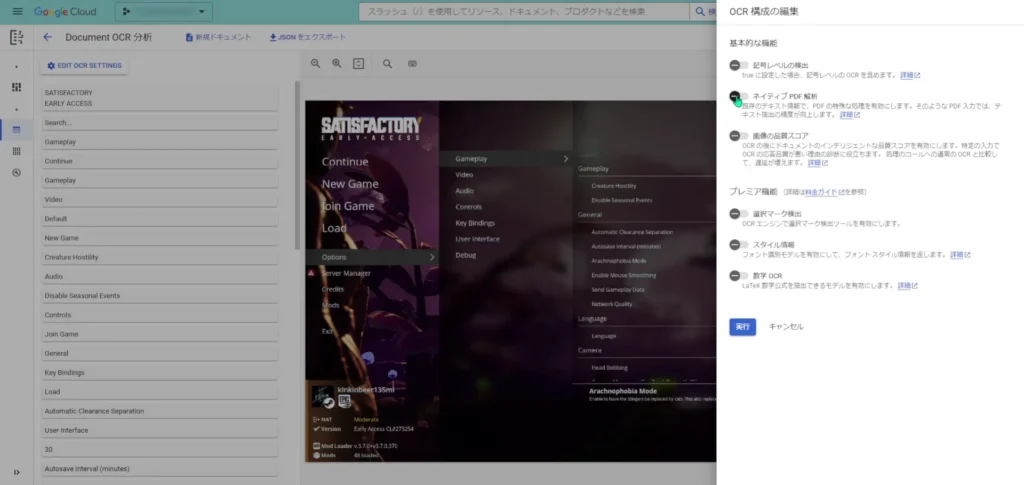
ちなみに、「Document OCR」では、OCR構造を細かく編集することが出来ます。
プレミア機能を使えば、論文などからLaTeXなどで書かれた公式のOCRも出来るみたいです。
生成AIに学習させて使用する「カスタムプロセッサ」を試す
Document AI標準のプロセッサ2つを試して、使用感が微妙だったので、もう少し踏み込んでいきたいと思います。
Document AIのサービスでは、生成AIに学習させて使用する「カスタムプロセッサ」なるものを作成して活用することが出来るみたいなので、次にこれを試していきます。
このマイプロセッサ一覧画面から、「カスタムプロセッサを作成」をクリックします。
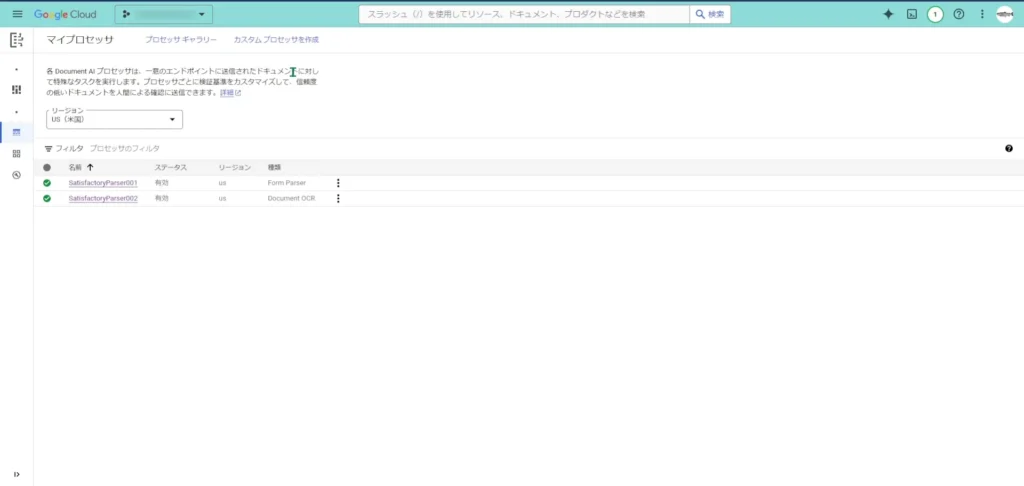
すると、「ワークベンチ」画面に遷移します。
Document AIで作成できるカスタムプロセッサの種類は、2024-04-20時点では4種類のようです。
「Custom Extractor」、「Custom Classifier」、「Custom Splitter」、「Summarizer」のようですね。
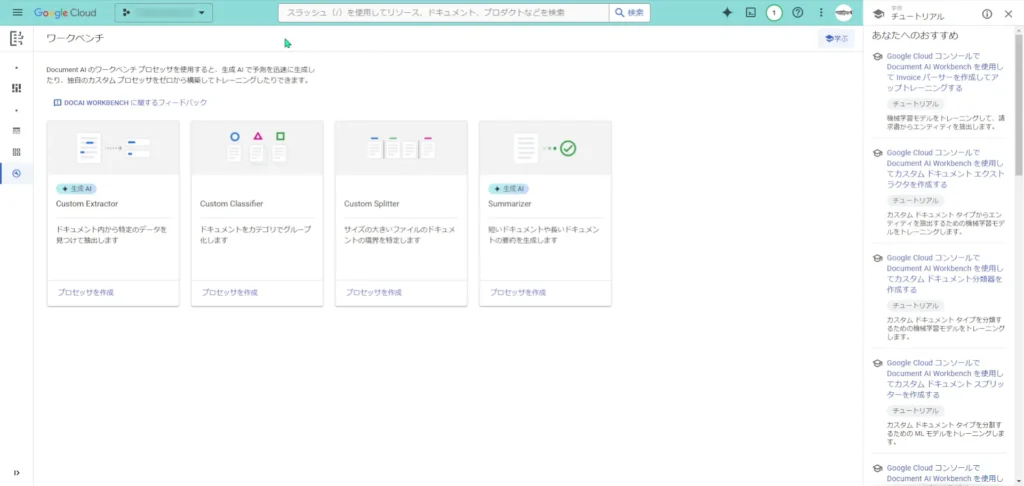
今回は、個々のゲーム設定画面の画像を使って学習させていきたいので、「Custom Extractor」を選択します。
選択すると、標準プロセッサと同様のお決まりの設定メニューが表示されるので、お決まりの設定をしていきます。
一つだけ、「ストレージの選択」という項目を追加で設定する必要があるので、「Googleが管理するストレージ」を選択してプロセッサを作成します。
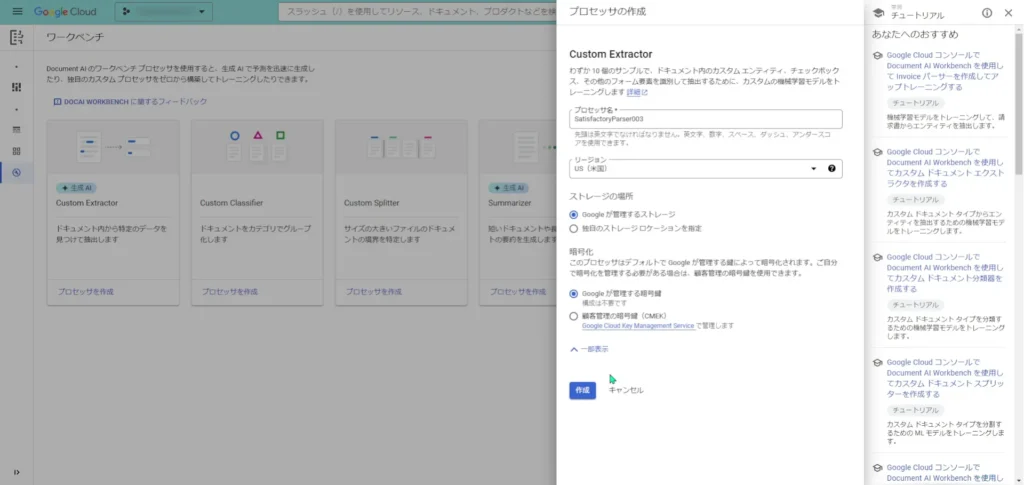
カスタムプロセッサが作成されると、標準プロセッサとはまた少し違った画面が表示されます。
このプロセッサには、追加で学習させることが出来るので、「スキーマの定義とプレビュー」や「ビルドバージョンを作成する」ことが出来るようです。
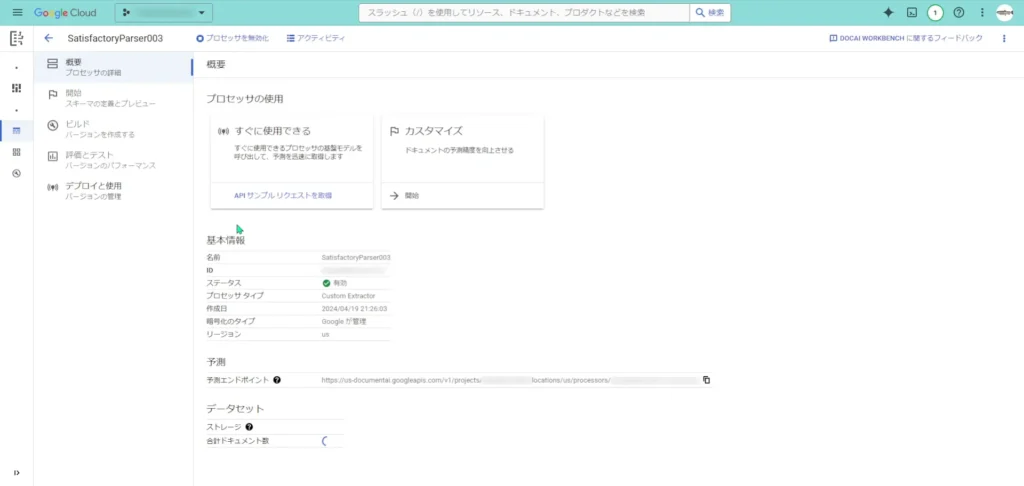
まずは一旦、このプロセッサの「データセット」が反映されるまで待ちます。このデータセットの反映が終わらないと、追加で学習させることが出来ません。
反映される前に、学習させるための新しいデータセットを入れようとすると、こんなアラートが表示されます。
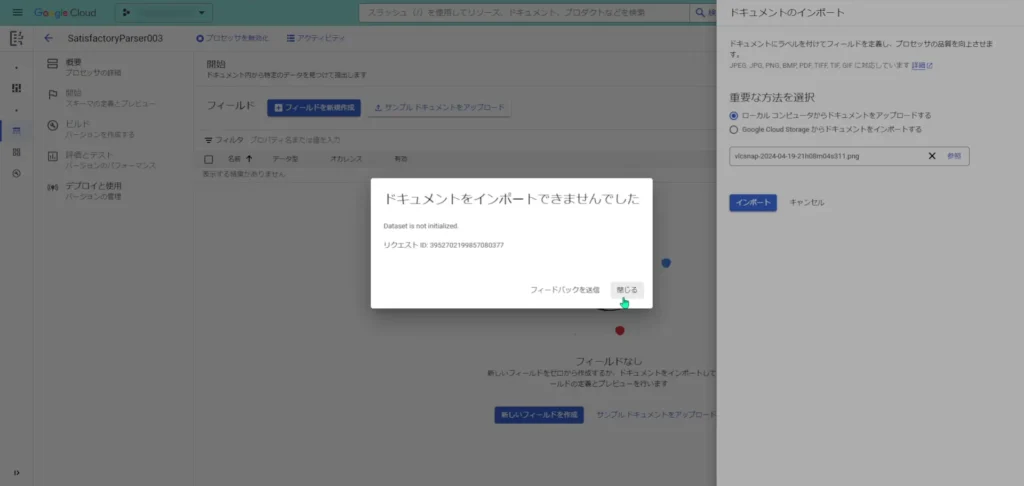
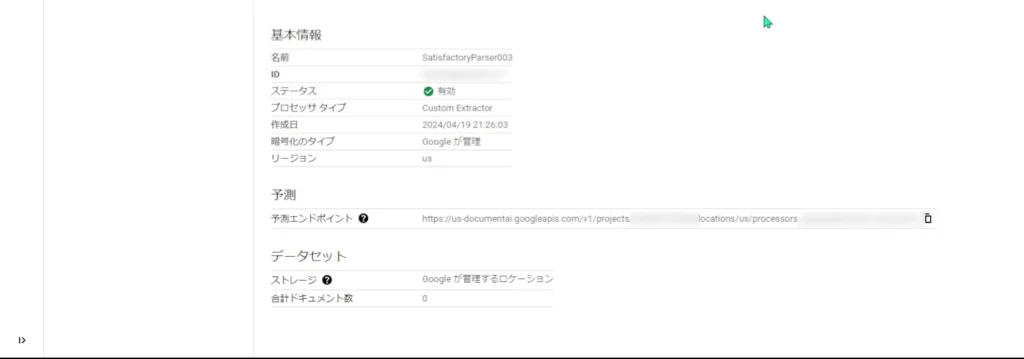
ということで反映されるまで待つと、「データセット」の部分で「Googleが管理するロケーション」といったような表示がされますので、そうしたら学習の開始です!
「Custom Extractor」への学習データセットを作る
カスタムプロセッサ:「Custom Extractor」を学習させていく流れは、①画像のアップロード、②フィールドの編集になります。この流れをひたすら繰り返していきます。
最初のカスタムデータセットを作る
まずは、①画像のアップロードです。
アップロード元は、ローカルPC側からと、Google Cloud Storageからでも行えるようですね。
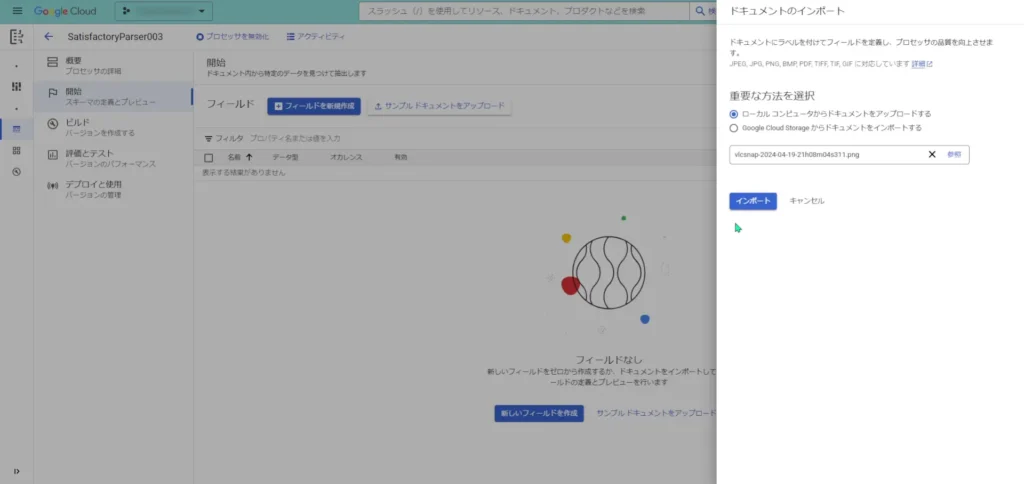
画像をアップロードしてデータセットとしてインポートされると、このような画面が表示されます。
最初にあらかじめカスタムプロセッサがOCRで文字列だと判断した箇所が表示されます。
我々ユーザーは、①その箇所が正しいかどうか、②その判断した箇所に過不足がないかどうか、③フィールドが間違っていないかどうかなどをチェックしていきます。
最初は、フィールドをただ一つも設定していないので、カスタムプロセッサが抽出した箇所は0件になっているようですね。
それでは、我々ユーザー側から、「フィールド」を設定していきたいと思います。
「新しいフィールドを作成」をクリックすると、「新しいラベルを作成」ダイアログが表示されて新規作成することが出来ます。まあ、、、「フィールド」も「ラベル」も同じようなものなのでしょう。
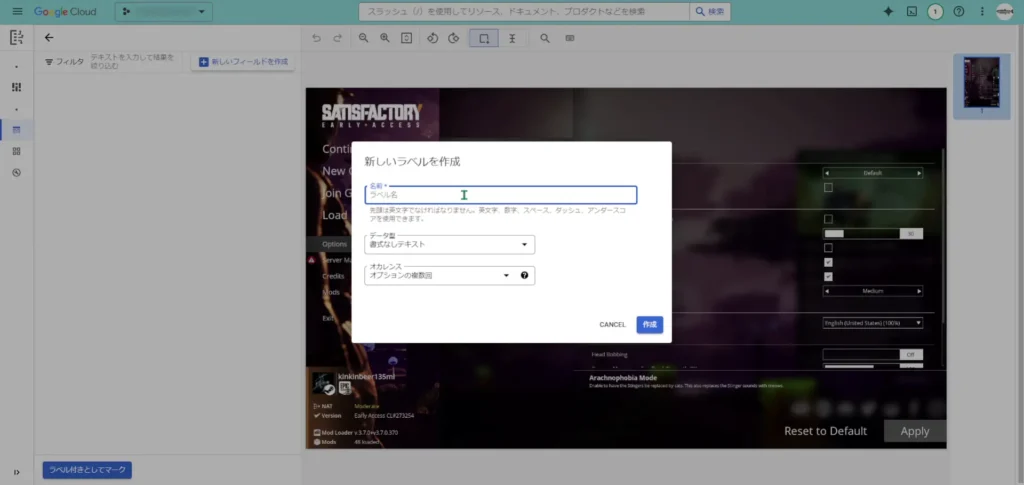
まずは、「大項目」を抽出するためのラベル:「pi01」を作成します。
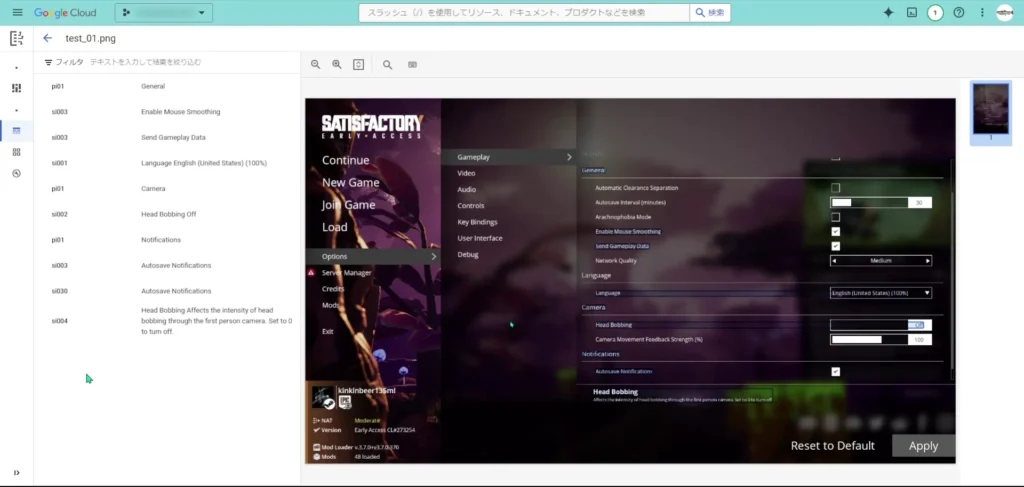
「Satisfactory」というゲームの大項目>中項目といった感じで設定項目が羅列されています。そのため、まずは大項目を読み取るラベルを以下のように用意します。
「オカレンス」は、そのラベルが一つの画像の中にいくつ存在するものなのかを設定する項目になっています。大項目は、一つの画像の中で複数回存在する可能性があるので、「オプションの複数回」で設定します。
ラベル:「pi01」を作成しました。
そうしたら、そのラベルで抽出したい箇所を、画像の中をクリックして範囲選択をします。
範囲選択をすると、付与したいラベルをラベル一覧から選択できますので選択します。
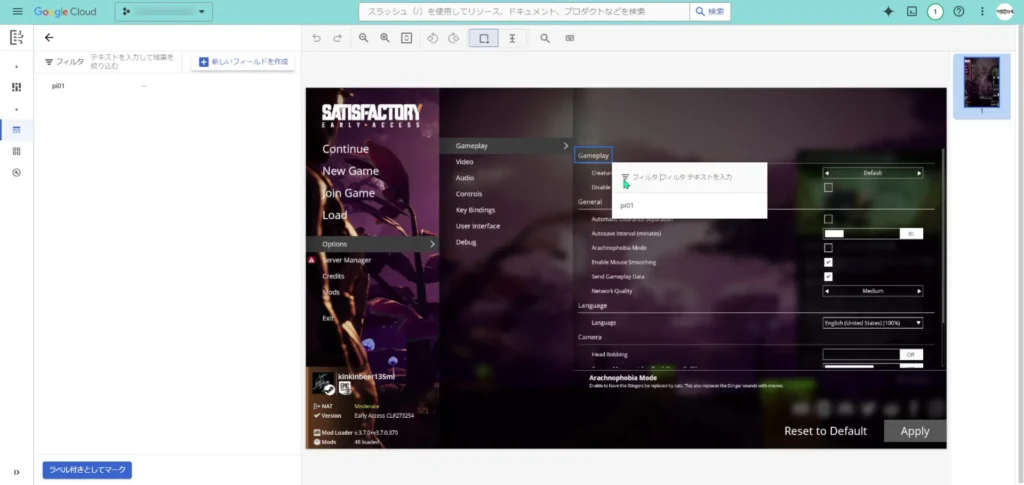
ラベルを付与すると、ラベル一覧の中に、「pi01」が付与された1件の範囲が追加されました。
この処理を繰り返して、データセットを増やしていきます。
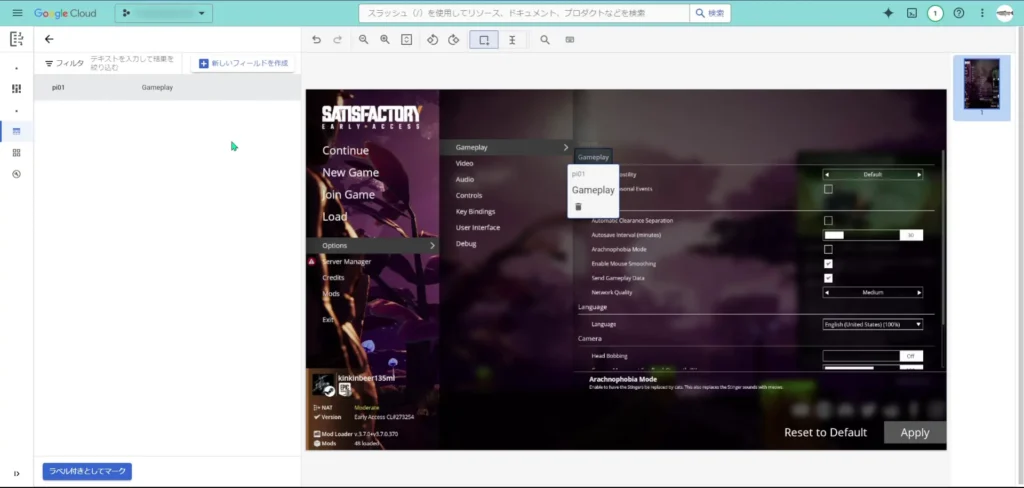
次に、「si001」ラベルを作ります。このラベルは、中項目を抽出するためのラベルになります。
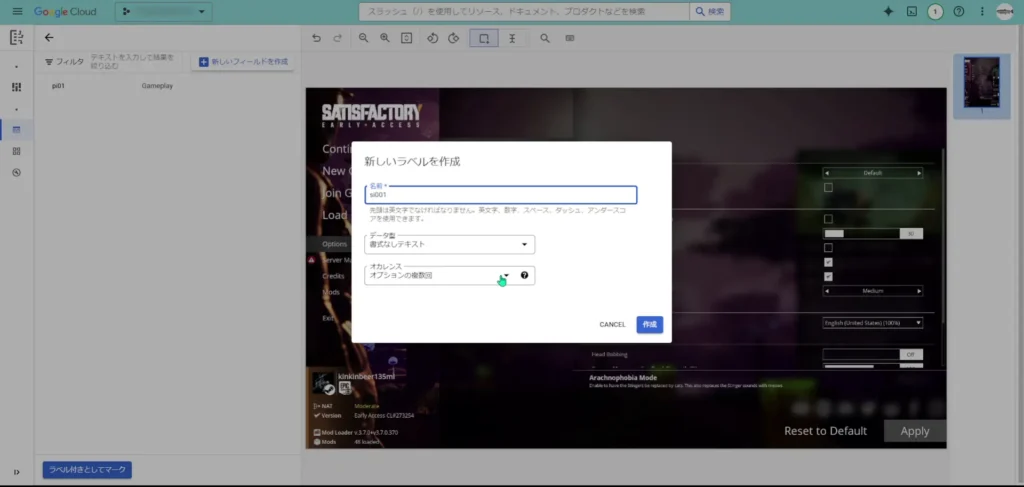
この中項目用のラベル:「si001」で、「Gameplay」直下の項目「Creature hostility」を、値も含めて抽出します。
「si001」は、「Creature hostility」のように左右をクリックすることで値を選択する形式の項目だけに適用するラベルとしたいと思います。
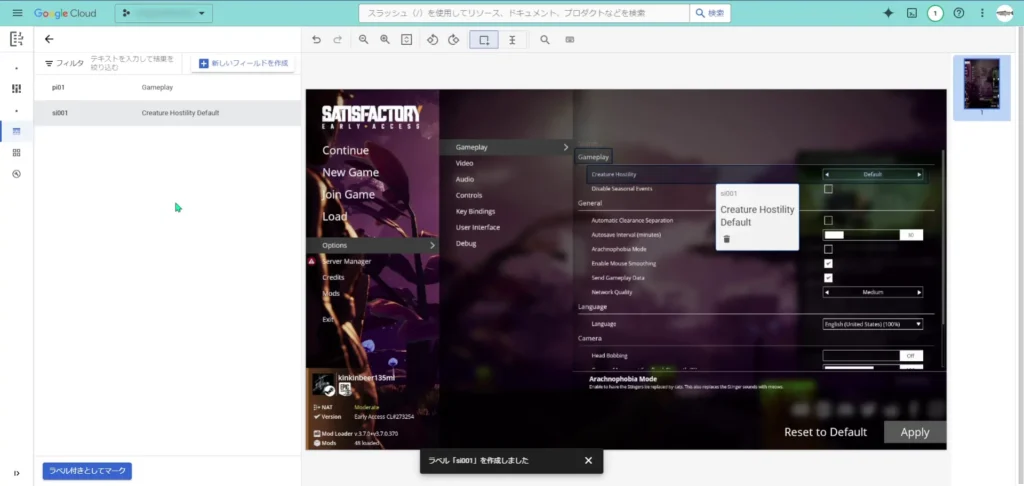
同様に、ラベルを増やしていって、最初の画像にはラベルを設定し終えました。
そうしたら、「ラベル付きとしてマーク」をクリックして、ラベル付きのデータセットとして保存します。
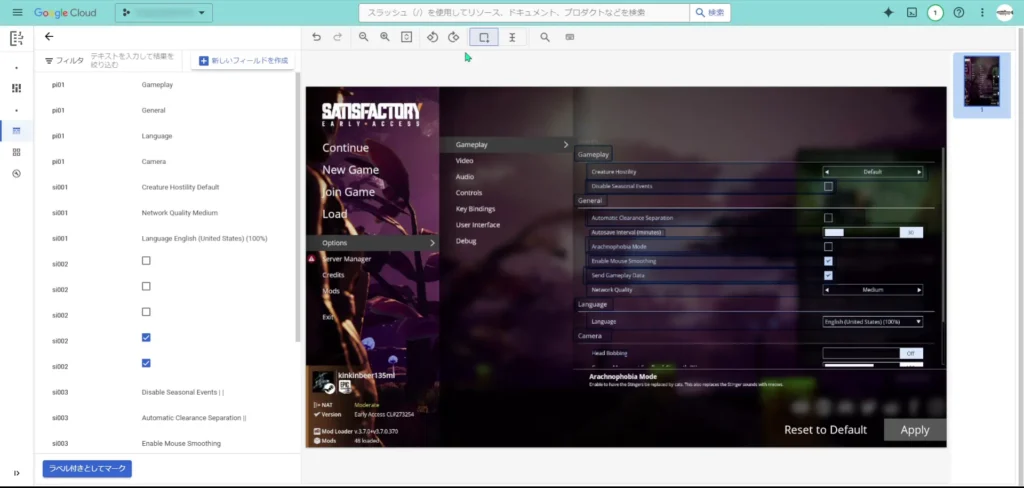
2番目以降のカスタムデータセットを作る
次に、2枚目の画像をインポートして、先ほどと同じ要領でデータセットを作っていきます。
ちなみに、1つ目のデータセットがラベル付きとして保存されたので、今回のカスタムプロセッサのフィールド一覧の画面に先ほど設定したラベルが表示されていますね。
それでは、先ほどと同じサイドメニューを表示させて画像をアップロードしてインポートしていきます。
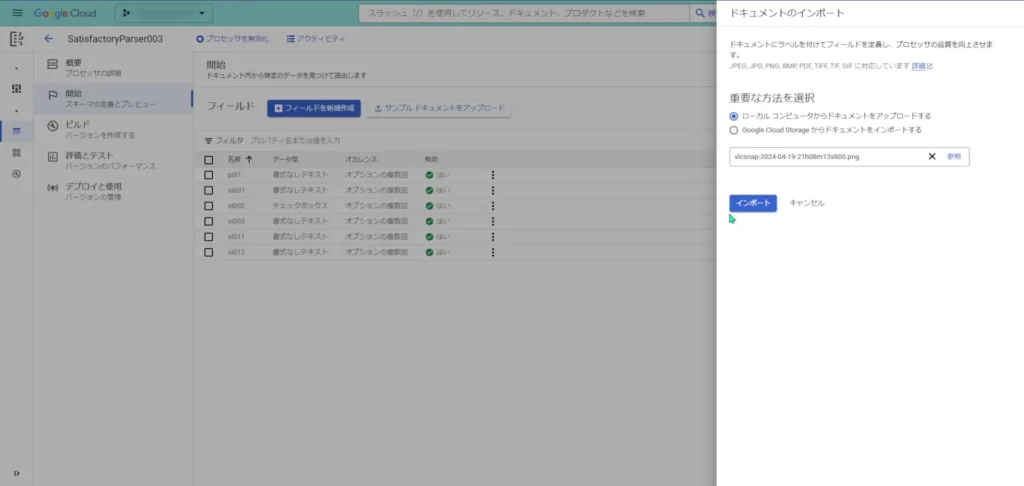
すると、2枚目以降からは、既に設定したラベルが存在していますので、そのラベルの情報から生成AIによって自律的にOCRが行われています。
しかし、まだカスタムデータセットが1件しか無いからか、内容的には満足できるものとはなっていません。
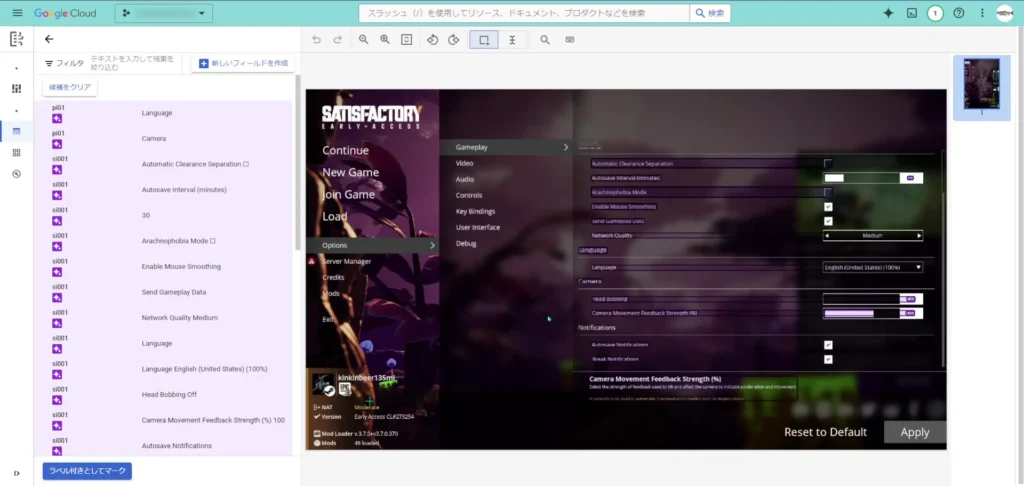
生成AIが判断した箇所を選択すると、「確認」のUIが追加されています。
抽出された内容に問題がなければ、「確認」をクリックすることでそのままデータセット内で反映されます。問題があれば、再び編集していきます。
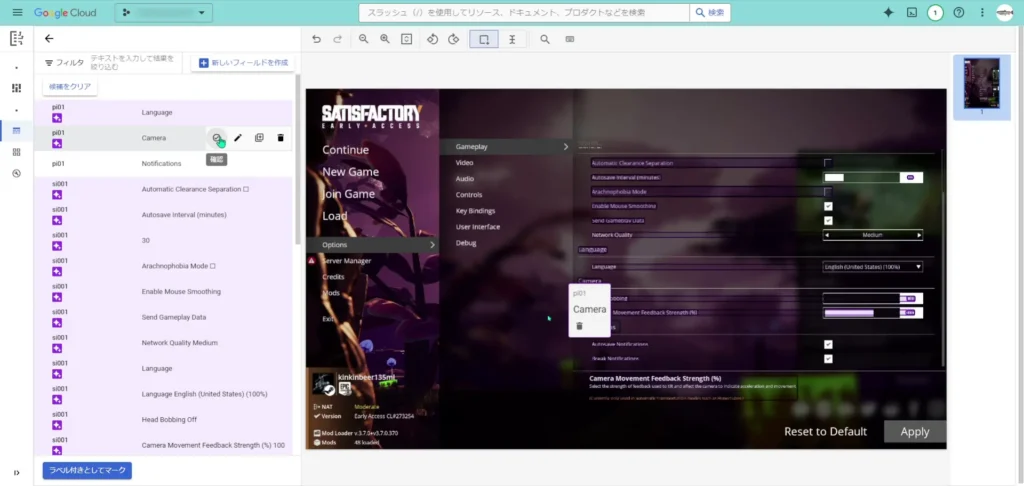
Satisfactoryの設定画面には、チェックボックスを使って設定する項目もあるので、その項目には「チェックボックス」としてラベルを付与していきます。「チェックボックス」では、チェックされているかどうかを設定できます。
この他にも、スライダー形式の項目や、ドロップダウンボックス形式の項目があったりするので、それぞれ別のラベルとして付与していきました。
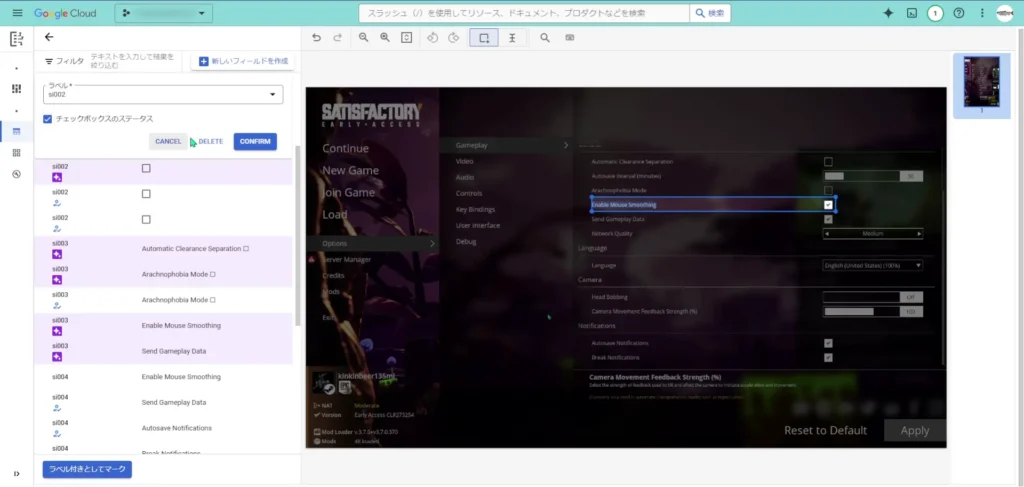
学習が終わったら、テストをしていく
それでは、学習が終わったら今度は標準プロセッサにも行ったように、テストをしていきます。
今回の学習結果として、合計23枚の画像をカスタムデータセットとして使用し、付与したラベルは以下のようになりました。
| ラベル名 | 意味合い |
|---|---|
| pi01 | 大項目 |
| si001 | ドロップダウンボックスの選択項目のプロパティ及び値 |
| si002 | チェックボックスの値 |
| si003 | チェックボックスに対応するプロパティ(false) |
| si004 | チェックボックスに対応するプロパティ(true) |
| si005 | チェックボックスに対応するプロパティ及び値(false3縦) |
| si006 | 左右切替ボックスの選択項目のプロパティ及び値 |
| si011 | スライダー式の項目のプロパティ及び値 |
| si020 | 値のUIが存在しないプロパティ |
| si030 | 自由入力項目 |
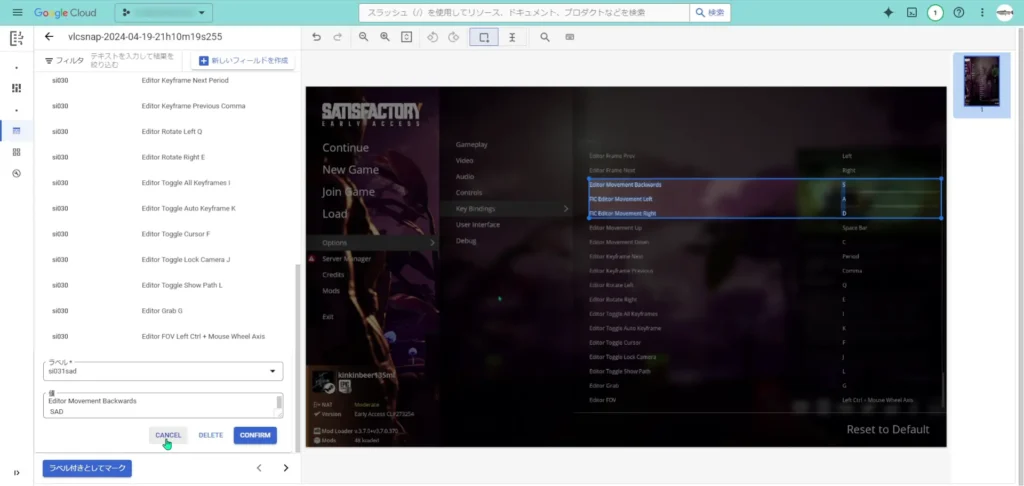
| si031sad | 自由入力項目SAD対策 |
| si040 | カラー入力項目 |
「自由入力項目SAD対策」や「チェックボックスに対応するプロパティ及び値(false3縦)」は、OCRが、「S」「A」「D」が縦に並んでいる場合に「sad」という単語として認識してしまったり、チェックボックスが縦に3つある場合に「□□□」という文字列として認識してしまう事象への対策としてラベルになっています。
標準プロセッサへのテストと同様に画像をアップロードしてテストしていきます。
この「評価とテスト」画面で「テストドキュメントをアップロード」をクリックしてテストしていきます。
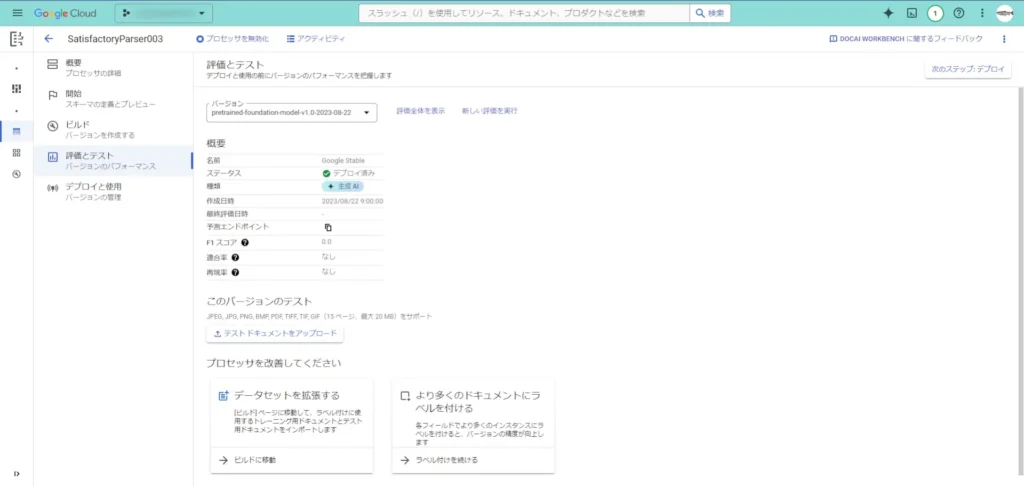
そうしたら、テスト結果が表示されました。
しかし・・・、あまり結果が芳しくないです・・・
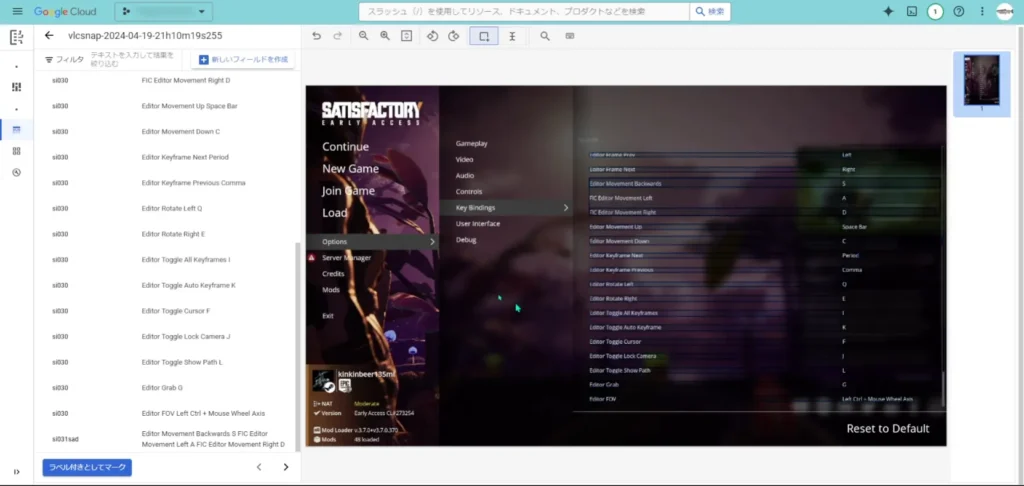
結果が芳しくなかった原因としては、2つ考えられて、①「SAD対策」に対するデータセットが少なすぎること、②「自由入力項目」のデータセットが多すぎて過学習が起きていること、が考えられます。
今回、Satisfactoryの設定画面を最初から最後までスクショして、それら全てをデータセットとして利用しました。そして、「自由入力項目」の設定項目は、他の設定項目の2,3倍以上は存在するので、データセットが他の設定項目より多くなってしまいました。
まとめ
このブログ記事では、Google CloudのDocument AIを使用してゲーム「Satisfactory」の設定を管理する方法を紹介しました。以下が記事の要点です:
- Document AIの基本とその設定方法
- 標準プロセッサ「Form Parser」と「Document OCR」の使用体験
- カスタムプロセッサ「Custom Extractor」の作成と訓練
- 複数のカスタムデータセットを作成して学習させるプロセス
- 実際のテストと評価
以上の内容を通して、ゲームの設定を効率的に管理する方法を構築しようとしましたが、今回は上手くいきませんでした。
問題と思われる箇所を修正すれば使えるようになるのかもしれませんが、このデータセットの作成が、作業に5時間以上掛かりなかなかに泥臭く、もう少しデータを増やすとなるとさらに時間を要するので、この方法はあまり効率的ではないのかもしれません。
もう少しAIへの学習に慣れる必要がありそうです。それまでは一旦、ゲームの設定は画像として管理していこうと思います・・・。
あと、最後にプロセッサのデプロイを切るのを忘れないようにしましょう!(プロセッサのステータスが「無効」になっていることを確認!)
財布が力尽きてしまいます!
おしまい
う~ん、人生って厳しいなあ・・・
けっこう泥臭いよな・・・
以上になります!


コメント