
はじまり
あー! また下書きを書かずに投稿してしまったー!
おお? このブログの話かね?
思いの外、指が動いてしまって、投稿しちゃうんだね。
うむ、だが下書きを書いておかないと、なにか起きてブログのサーバーとかが死んだ時にリスタートできないのが心配なんだよな・・・。
・・・よし! 作るぞ、おれは作るぞ! 既に書いてしまったものを下書きにしてしまうツールを作るぞおお!
逆にね。本番環境を手修正したから、受入環境に本番環境をリリースする的なノリだね。
まあ、その状況とは違って、今回は下書きというものが存在しないから、特に危険なことはないけどね。
よっしゃ! はじまるよ~。
ツールの概要
ツールの概要をざっと紹介します。
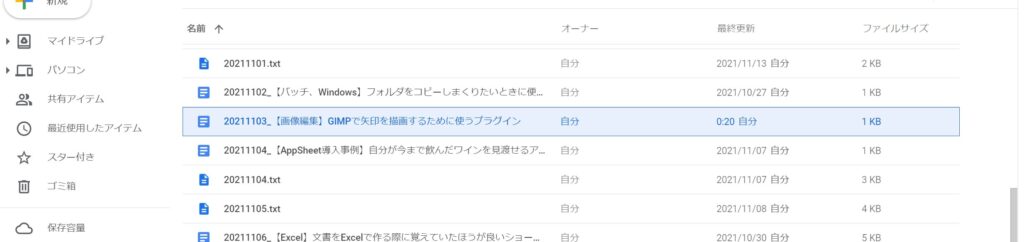
僕はGoogleドライブの所定のフォルダに今まで書いたブログの記事の下書きを管理しているのですが、たまに下書きを書かずにWordPress上で公開まで行ってしまう記事があります。(例えば、この記事は「20211103」のIDが付いているのですが、その記事の下書きはありません。)
その際にこのツールが実行されると、Googleスプレッドシートで管理している台帳で公開済みになっている記事の内容を読み取って、Googleドキュメントとして出力してくれます。
ツールのソース
ツールのソースはこんな感じです。
コード.gs
var draftFolderId = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX';
function getAlreadyPostedList(postedList) {
// declare for prepare.
var alreadyPostedList = [], alreadyPostedChr = '済';
// get list of aticle already posted.
postedList.forEach(function(value) {
if(value[1] == alreadyPostedChr) {
alreadyPostedList.push([value[0], value[2]]);
}
});
return alreadyPostedList;
}
function readGssColumns() {
// declare for prepare.
var ss,
sheetName = 'ブログ_記事',
sheet,
postedNumber,
row_for_postedNumber = 6,
column_for_postedNumber = 13;
ss = SpreadsheetApp.getActive();
sheet = ss.getSheetByName(sheetName);
postedNumber = Number(sheet.getRange(row_for_postedNumber, column_for_postedNumber).getValue());
// declare for get list from GSS.
var dateList = [],
dateList_formated = [],
permalinkList = [],
permalinkList_formated = [],
postedList = [],
i = 2, // index of row to start reading sheet.
column_for_date = 3, // index of 「起票日」column.
column_for_posted = 6, // index og 「投稿済」column.
column_for_permalink = 7, // index of 「パーマリンク」column.
returnList = [];
// get dateList and cleansing.
dateList = sheet.getRange(i, column_for_date, postedNumber, 1).getValues();
for (let j = 0; j < postedNumber; j++) {
dateList_formated.push(Utilities.formatDate(dateList[j][0], 'JST', 'yyyyMMdd'));
}
// get permalinkList and cleansing.
permalinkList = sheet.getRange(i, column_for_permalink, postedNumber, 1).getValues();
for (let j = 0; j < postedNumber; j++) {
permalinkList_formated.push(permalinkList[j][0]);
}
// get postedList.
postedList = sheet.getRange(i, column_for_posted, postedNumber, 1).getValues();
// create returnList
for (let k = 0; k < postedNumber; k++) {
returnList.push([dateList_formated[k], postedList[k][0], permalinkList_formated[k]]);
}
return returnList;
}
function readYetReadArticles(postedList) {
// declare for prepare.
var alreadyPostedList = getAlreadyPostedList(postedList);
// declare for prepare.
var yetReadList = getYetReadList(alreadyPostedList);
return yetReadList;
}
function exportYetReadArticles(yetReadArticlesList) {
// declare.
var targetUrl = 'https://www.endorphinbath.com/',
getUrl,
html,
articleTitle,
articleText,
editFile,
editFileId,
docFile,
body_docFile,
docFileName,
endOfText = '<p>以上になります!</p>\n </div>',
errorDocFile,
body_errorDocFile,
today = new Date();;
// テンプレートファイル(「yyyyMMdd(E)」)
var templateFile = DriveApp.getFileById('YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY');
// 出力先フォルダ
var outputFolder = DriveApp.getFolderById(draftFolderId);
// 「ErrorLog_Batch」Docファイル
errorDocFile = DocumentApp.openById('ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ');
body_errorDocFile = errorDocFile.getBody();
var paragraph = body_errorDocFile.appendParagraph(Utilities.formatDate(today, 'JST', 'yyyyMMdd') + '---ErrorLog---\n');
// Read articles not read yet and which draft is nothing.
yetReadArticlesList.some(function(value) {
getUrl = targetUrl + value[1];
html = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
// Get articleTitle and cleansing.
articleTitle = String(Parser.data(html).from('<h1 class="entry-title" itemprop="headline">').to('</h1>').iterate());
articleTitle = articleTitle.replace(/\n /g, '');
articleTitle = articleTitle.replace(/ /g, '');
// Get articleText and cleansing.
articleText = String(Parser.data(html).from('<div class="entry-content cf" itemprop="mainEntityOfPage">').to(endOfText).iterate());
articleText = articleText.replace(/p>\n\n\n\n<p>/g, 'p>\n<p>');
// Check whether scraping is correctly.
docFileName = value[0] + '_' + articleTitle;
if (articleText.indexOf('<h2><span id="toc1">はじまり</span></h2>') != -1) {
// Copy document with articleTitle.
editFile = templateFile.makeCopy(docFileName, outputFolder);
editFileId = editFile.getId();
docFile = DocumentApp.openById(editFileId);
body_docFile = docFile.getBody();
// And write articleText.
body_docFile.clear(); // 全消去
var paragraph = body_docFile.appendParagraph(articleText);
console.log(editFileId);
}else{
var paragraph = body_errorDocFile.appendParagraph(docFileName + '\n');
}
});
var paragraph = body_errorDocFile.appendParagraph('\n\n');
}
function getYetReadList(alreadyPostedList) {
// declare for prepare.
var yetReadList = [];
// declare for prepare.
var folder_id = draftFolderId, // Folder ID of draft for article.
folder,
files,
file_now,
date_format_8 = "yyyyMMdd";
// get list of folders.
folder = DriveApp.getFolderById(folder_id);
// get list of aticle not read yet.
alreadyPostedList.forEach(function(value) {
files = folder.getFiles();
while(files.hasNext()) {
file_now = files.next();
// If draft of article exitsts, break while loop.
if (value[0] == file_now.getName().substring(0, date_format_8.length)) {
break;
}
// If draft of article is nothing, ...
if (files.hasNext() == false) {
// If Permalink is not null, ...
if (value[1] != "") {
// Push Article into list.
yetReadList.push([value[0], value[1]]);
}
}
}
});
return yetReadList;
}
function exportPostedArticles() {
// declare for execute.
var postedList;
postedList = readGssColumns();
yetReadArticlesList = readYetReadArticles(postedList);
exportYetReadArticles(yetReadArticlesList);
}ツール作成時のハイライト
1. iteratorの初期化を忘れてハマった。
実際にハマった部分がここです。
getYetReadList(alreadyPostedList)
// .... (abbreviate) ....
files = folder.getFiles();
// get list of aticle not read yet.
alreadyPostedList.forEach(function(value) {
while(files.hasNext()) {
file_now = files.next();
// If draft of article exitsts, break while loop.
if (value[0] == file_now.getName().substring(0, date_format_8.length)) {
break;
}
// If draft of article is nothing, ...
if (files.hasNext() == false) {
// If Permalink is not null, ...
if (value[1] != "") {
// Push Article into list.
yetReadList.push([value[0], value[1]]);
}
}
}
});
return yetReadList;
return yetReadList;でどう足掻いても要素が1つしか出力されず、その解析に時間が掛かりました・・・。
原因は、filesがwhile文の中のiteratorの役割になっていますが、そのiteratorをforEach文の外で代入していたのが、そのバグの原因でした。そのせいで、for文が2回目に入る時に、iteratorが再代入されなかったのです。
先程貼った全ソースの中では、iteratorの代入文をforEachループの中に入れたので、解決しています。
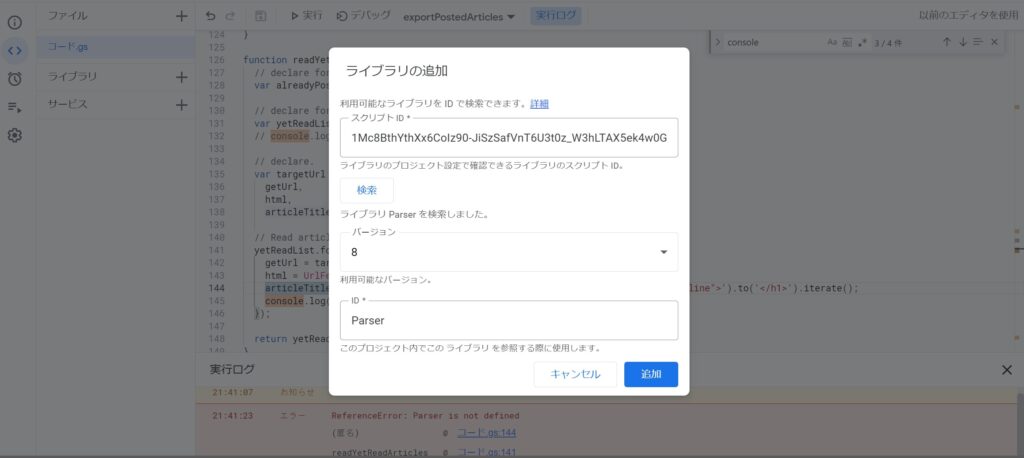
2. ParserをGAS上のライブラリに追加する。
今回、GASで初めてスクレイピングを導入して、GAS上の「ライブラリ」という部分を初めて触りました。
「ファイル」「コード.gs」「ライブラリ」「サービス」と項目が並んでいるので、その右側の「+」ボタンをクリックして、ライブラリの追加をしました。スクリプトIDは「1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw」で、検索するとこんな風に表示されるのでその状態で「追加」をクリックします。
おしまい
おーし、網羅できたぞー。とりあえず、下書き云々カンヌンを気にせずに執筆できるようになりましたとさ。
以上になります!
おい! やめろ!!
スクレイピングに使ってる識別文字列の一部を無闇に使うんじゃねえ!!
てへぺろ。
でも、まさかこの締めの言葉が役に立つとはねえ。
うん、まさしく、このツールを組むまで儀式的にこれで締めていたが、まさかこんなところで役に立つとは・・・(笑)
忘れたら、エラーログを吐くようにしといたし、これからも引き続きやっていきますわ。
以上になります!


コメント