
はじまり
なんだこれ生成AIに聞いても全然わからないよぉぉ!??
複数ページのPDFを作るのがこんなに大変だとは・・・。
事の発端はこんなところから。
以前にこの記事で、自分がHDDに溜めていた画像ファイルをwebp形式に変換するツールを作りました。

このツールを使うことで、確かに一つ一つのファイルのサイズはかなり小さくなったのです。
しかしその代わりに、新品のHDDを使っているくせに、「ディスクフラグメンテーション」的な現象が起きるようになっていきました。
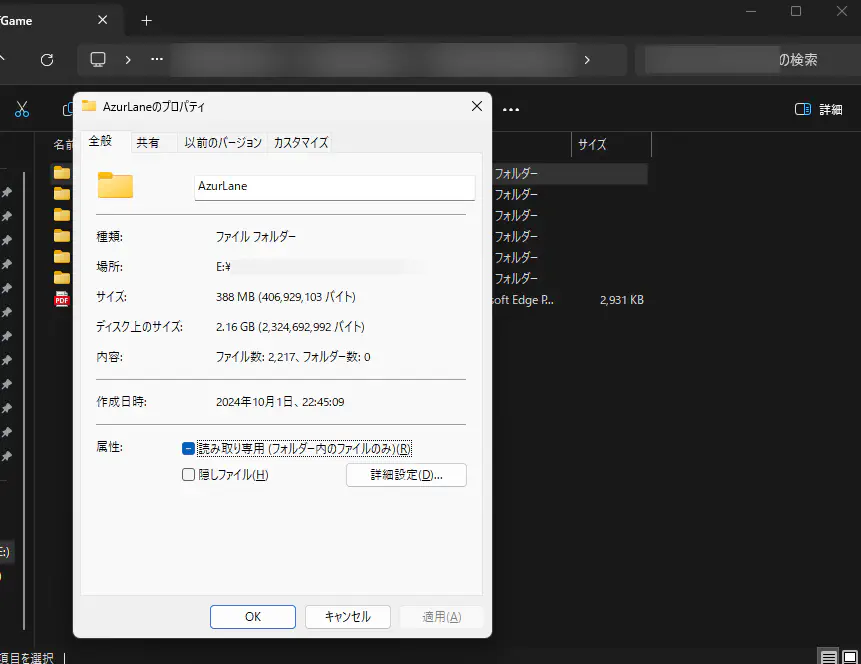
この画像は、大量のwebp画像を格納したフォルダのプロパティを表示したものです。
ここで、「ディスク上のサイズ」が「サイズ」よりも遥かに大きい数値になっていることが確認できます。1.8GBぐらい無駄になってますよ・・・。
PCで使うディスクの中身は、トラックの中にセクタがあって、セクタがクラスタでまとまってたりしますよね。
webpのようにサイズが小さいファイルでデータを保存すると、そのクラスタの中にデータが入り切らず、かなりのスペースが使われないまま放置される状態が出来上がってしまうわけですね。
ディスクをフォーマットしてクラスタのサイズを小さくすれば、このディスクの無駄遣い、デッドスペースは減らせそうですが・・・。
実はこの画像で使っているディスクはSSDです。それなのに、なんだかせっかく速く動けるSSDに対して、変にフォーマットして動きが遅くなったりしても困ってしまいます・・・。なのでなるべくディスクはこのままで使っていきたい・・・。
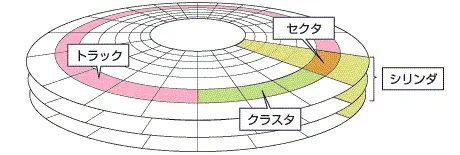
(トラックとセクタとクラスタ、そしてシリンダも一度に確認できる素晴らしい図解ですね。ソースはここ。)
小さくて細かい画像はPDFで一纏めにする
そこで、小さい沢山のwebp形式の画像を、複数ページを持ったPDFとしてまとめようと考えました。そうすれば、ディスクのフラグメンテーションは起こらないはず。
そのPDFを一つに結合するためのツールとして、「iLovePDF」というWebアプリを使ってみます。

このiLovePDFは、PDFの結合、分割、Excel⇔PDFでの変換などを行うことが出来ます。そしてその多様な機能の中で、「JPG PDF 変換」の機能を使って、大量のwebp画像をまとめていきたいと思います。(webpはiLovePDFに使えないので、「dwebp」を使ったりしてJPGやPNG形式に変換しておきます。PNGはいけるんですよね。)
そうすると・・・・・・アレッ・・・??
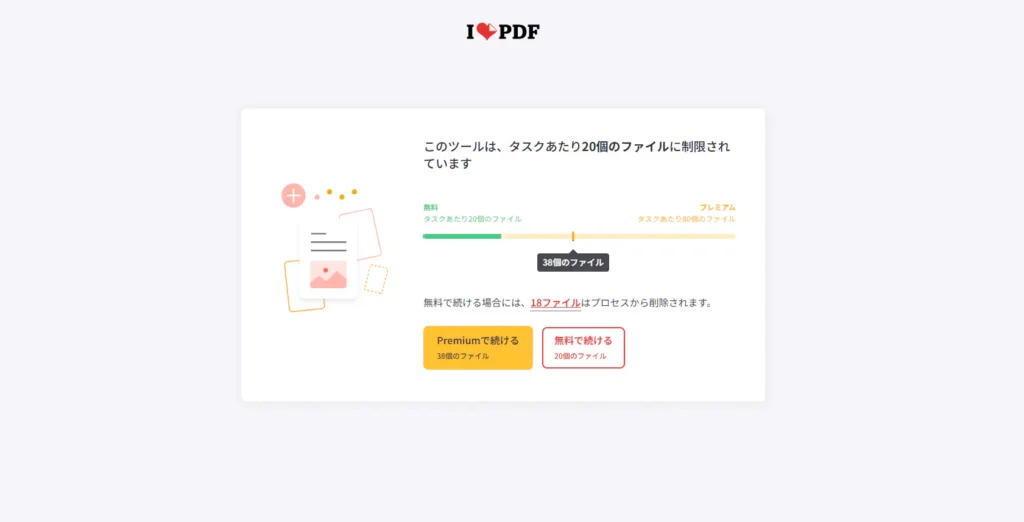
まさかのプレミアムプランに加入しないと21枚以上の画像をまとめられないパターン。
それに加えて、プレミアムプランに加入したとしても、80枚までの画像しか一つのPDFにまとめられないみたいですね。それだと話が違ってくるな・・・。他になんか良いツールは無いか・・・。
Windows標準の印刷アプリでは設定項目が粗い。
次に、「Windows標準の印刷アプリで一気にPDFとして印刷する」作戦に打って出ました。
エクスプローラ上で画像ファイルを複数選択した状態で右クリックをすると、コンテキストメニューが表示されますので「その他のオプションを表示」をクリックすると、また違ったコンテキストメニューが表示されますので、そこ「印刷」をクリックします。
しかし、この印刷ツールのUIを見渡してみると・・・、
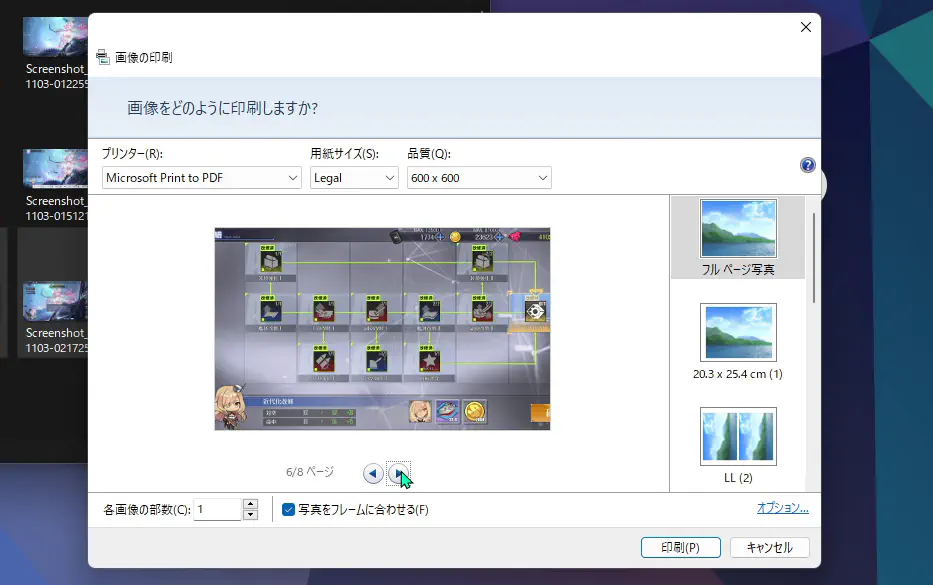
なんか設定できる項目が少なくないか・・・?
用紙サイズは変えられるみたいですが、縦で見たいものを縦向きには出来なさそうだし、余白とかも消せないのか・・・。縦と横の混合とかも出来ない?
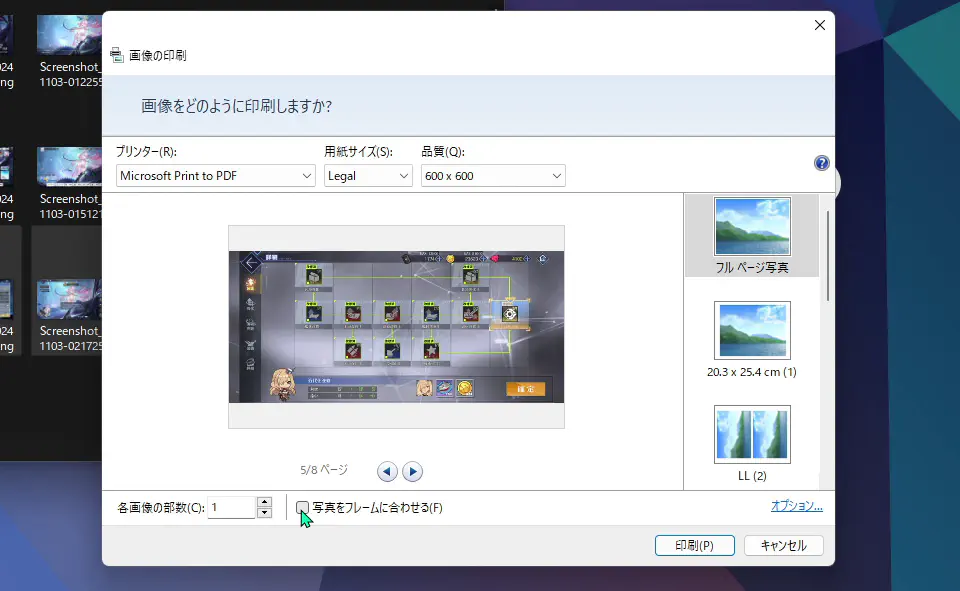
画像ファイルを複数選択した状態で、右クリック→「その他のオプションを表示」→印刷をクリック。
この操作では、プリンターの設定が十分に行えないみたいです。実際に紙に印刷したいわけではなく、フラグメンテーションを無くしたいだけだから、紙のサイズは元画像のものにしたいな・・・。
じゃあもうPowerShell使うしかないじゃん。
残念ながら、GUIを使ってシャカシャカとPDFへと結合することが出来なさそう感じがしてきました。
なので、PowerShellでPDF結合ツールを作ることにしました。PowerShellであれば別途ランタイムをインストールし直す必要とかありませんしね。
そこで最初に、「Microsoft Print to PDF」の仮想プリンターでPDFを出力できるようにしたいと思います。
そこで書いたのがこのコード。しかし、イイ感じに動きません・・・。
function Merge-ImagesIntoPdfWithPrinter([array]$pathList) {
# Load assembly of .NET Framework
Add-Type -AssemblyName System.Drawing
$doc = New-Object System.Drawing.Printing.PrintDocument
$pdfName = "";
$isPdfNamed = $false;
Write-Host ("{0}: aaaaaaaaaaaaaaaaaaaaaaaaaaaaa`n" -f $MyInvocation.MyCommand.Name);
Write-Output $itemCount;
foreach ($path in $pathList) {
$imagePath = $path.FullName;
$printPageEvent = {
#[System.Drawing.Printing.PrintPageEventArgs]$_
$srcBmp = New-Object System.Drawing.Bitmap($imagePath);
$m = $_.MarginBounds;
if ($srcBmp.Width / $srcBmp.Height -gt $m.Width / $m.Height) {
$m.Height = $srcBmp.Height * $m.Width / $srcBmp.Width
}
else {
$m.Width = $srcBmp.Width * $m.Height / $srcBmp.Height
}
$_.Graphics.DrawImage($srcBmp, $m);
Write-Host ("{0}: hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh`n" -f $MyInvocation.MyCommand.Name);
Write-Output $script:printedCount;
Write-Output $script:itemCount;
$_.HasMorePages = $false;
$tmp = Read-Host "Input 'y' if you wanna move original images......";
$srcBmp.Dispose();
}
if ($isPdfNamed -eq $false) {
$pdfName = [io.path]::Combine($path.DirectoryName, $path.BaseName);
$isPdfNamed = $true;
}
$doc.add_PrintPage($printPageEvent);
}
$doc.PrinterSettings = New-Object System.Drawing.Printing.PrinterSettings;
$doc.PrinterSettings.PrinterName = "Microsoft Print to PDF";
$doc.PrinterSettings.PrintToFile = $true;
Write-Host ("{0}: vvvvvvvvvvvvvvvvvvvvvvvvvvvvvv`n" -f $MyInvocation.MyCommand.Name);
$doc.PrinterSettings.FromPage = 0;
$doc.PrinterSettings.ToPage = 3;
$ext = ".pdf";
$doc.PrinterSettings.PrintFileName = "{0}{1}" -f $pdfName, $ext;
Write-Output $doc.PrinterSettings.MinimumPage;
$doc.PrinterSettings.MaximumPage = 3
Write-Output $doc.PrinterSettings.MaximumPage;
Write-Host ("{0}: xxxxxxxxxxxxxxxxxxxxxxxxxxxxx`n" -f $MyInvocation.MyCommand.Name);
Write-Output $doc.PrinterSettings.ToPage;
$doc.Print();
$doc.Dispose();
}
$targetFolder = (Get-Location).Path;
$imgPathList = Get-ChildItem $targetFolder -Recurse -File -Include *.jpg, *.png -Exclude PDFsharp*;
Merge-ImagesIntoPdfWithPrinter $imgPathList;
$tmp = Read-Host "Input 'y' if you wanna move original images......";
何が問題なのかと言うと、出力されるPDFが1ページしかないからです。Read-Hostが現れる回数はページの数と合っているはずなのに、なぜなのやら・・・。
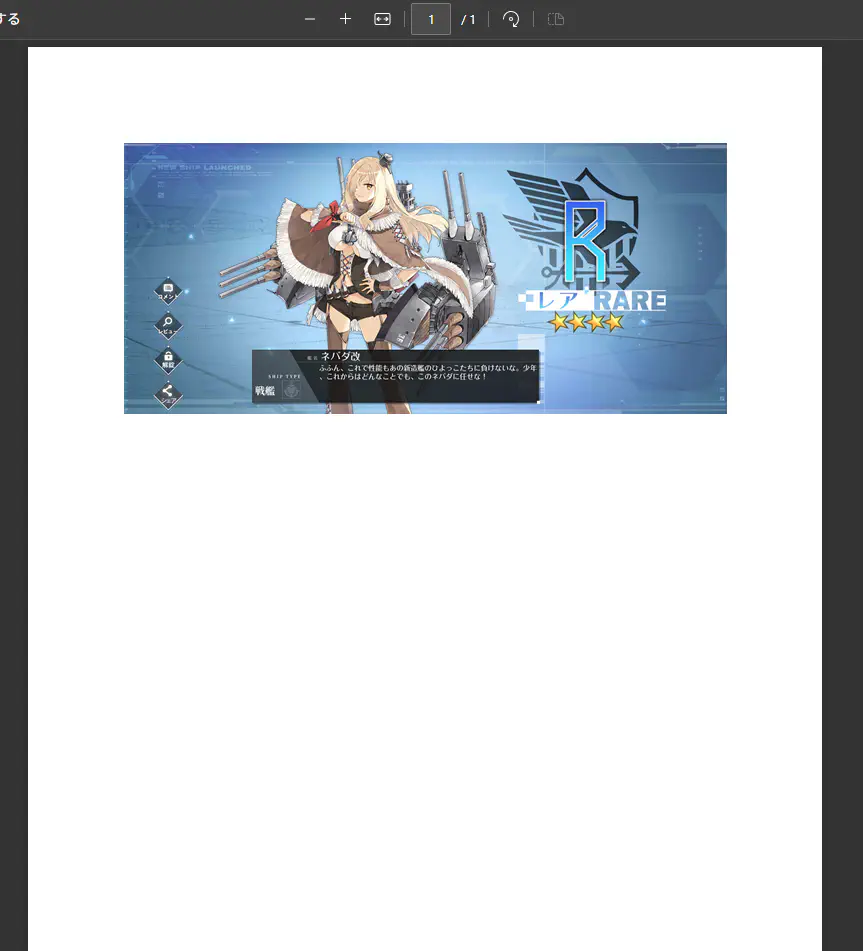
うーん・・・一体何がいけないんでしょう・・・。PrintDocumentクラスやら、PageSettingsクラスやら、PrinterSettingsクラスやらPrinterSettings.PrintRangeプロパティやら・・・、色々試しましたが、どうやっても1ページしか出力されません。
参考にしたコードは以下の記事になりますが、このコードに出てくるadd_PrintPageメソッドが一体どういう動きをするのかどうかが全く分からないんですよね。その名前空間のクラスのそのメソッドでググっても全然引っ掛からない・・・。

ググっても分からなければ、生成AIに頼ってみたりもするのですが、彼ら、add_PrintPageメソッドを使った殆ど同じような実装案しか出してこなかったりして、「Microsoft Print to PDF」を使った解決策を見出すことが出来ませんでした・・・。
なので、この方法での実装はスキップしました。
ps1ファイル一つで簡潔する方法なので、なるべくこの方法にしたかったですが仕方がありません・・・。
PDFsharpライブラリで実装する。
結局、iTestSharpライブラリで実装することになるんですけど、そのiTextSharpで一度躓いて、「PDFsharp」による実装を試したので、このライブラリでの過程も書いておきます。そうです、この方法でも失敗しました。
PdfSharpライブラリのNupkgをWeb上から手に入れて、7-Zipとかで解答すると「PdfSharp.dll」が手に入るので、そのDLLを色々叩いてはみるんですけど、どうしてもDLLをインポートするところでエラーになってしまうんですよね。
function Merge-ImagesIntoPdfWithPdfSharp([array]$pathList) {
# $pdfsharpFileName = "PdfSharp.dll";
$pdfsharpFileName = "pdfsharp.6.1.1\lib\net6.0\PdfSharp.dll";
# $pdfsharpFileName = "pdfsharp.6.1.1\lib\netstandard2.0\PdfSharp.dll";
$pdfsharpPath = "{0}\{1}" -f $pathList[0].DirectoryName, $pdfsharpFileName;
Write-Host ("{0}: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa`n" -f $MyInvocation.MyCommand.Name);
Write-Output $pathList;
Write-Host ("{0}: hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh`n" -f $MyInvocation.MyCommand.Name);
Write-Output $pdfsharpPath;
# Add-Type -Path $pdfsharpPath
# Add-Type -LiteralPath $pdfsharpPath
[System.Reflection.Assembly]::LoadFrom($pdfsharpPath);
# $error[0].Exception.GetBaseException().LoaderExceptions
Write-Host ("{0}: jjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjjj`n" -f $MyInvocation.MyCommand.Name);
$ext = ".pdf";
$pdfName = "{0}\{1}{2}" -f $pathList[0].DirectoryName, $pathList[0].BaseName, $ext;
$pdfDocument = New-Object PdfSharp.Pdf.PdfDocument;
foreach ($path in $pathList) {
$imagePath = $path.FullName.GetType().FullName;
Write-Output $imagePath;
Write-Output $imagePath.GetType().FullName;
Write-Host ("{0}: kkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkk`n" -f $MyInvocation.MyCommand.Name);
# 画像の読み込み
$image = [System.Drawing.Image]::FromFile($imagePath)
# ページの作成とサイズの設定
$pdfPage = $pdfDocument.AddPage()
$pdfPage.Width = [PdfSharp.PageSize]::A4.Width
$pdfPage.Height = [PdfSharp.PageSize]::A4.Height
# XGraphics オブジェクトで画像を描画
$gfx = [PdfSharp.Drawing.XGraphics]::FromPdfPage($pdfPage)
$xImage = [PdfSharp.Drawing.XImage]::FromFile($imagePath)
# 画像をページサイズに合わせてスケーリング
$gfx.DrawImage($xImage, 0, 0, $pdfPage.Width, $pdfPage.Height)
# リソースの解放
$xImage.Dispose()
$image.Dispose()
}
# PDF ドキュメントを保存
$pdfDocument.Save($outputPdfPath)
$pdfDocument.Close()
}
$targetFolder = (Get-Location).Path;
$imgPathList = Get-ChildItem $targetFolder -Recurse -File -Include *.jpg, *.png -Exclude PDFsharp*;
Merge-ImagesIntoPdfWithPdfSharp $imgPathList;
$tmp = Read-Host "Input 'y' if you wanna move original images......";
エラーメッセージ。フォルダパス内のユーザー名は伏せています。
“1” 個の引数を指定して “LoadFrom” を呼び出し中に例外が発生しました: “ファイルまたはアセンブリ ‘file:///C:\Users\xxxxxxxxxxxxx\Downloads\新しいフォルダー\新しいフォルダー\pdfsharp.6.1.1\lib\netstandard2.0\PdfSharp.dll’、またはその依存関係の 1 つが読み込めませんでした。操作はサポートされません。 (HRESULT からの例外:0x80131515)”
DLLのインポートの手段が2種類ぐらいありますが、どちらでやっても同じようなエラーになります。一体どこの依存関係が欠けているのか、ちょっとそれを調べるのには時間が惜しいですよね・・・。
# 方法1-1
Add-Type -Path $pdfsharpPath;
# 方法1-2
Add-Type -LiteralPath $pdfsharpPath;
# 方法2
[System.Reflection.Assembly]::LoadFrom($pdfsharpPath);iTestSharpライブラリで実装する。
そして、別の方法で実装しましたとさ。
「iTextSharp」でググれば沢山の情報が引っ掛かります。僕がiTextSharpを知ったのは、そもそも生成AIの回答からでした。それほど、ありふれたPDF編集ライブラリなのでしょう。
しかし、そんな恵まれた情報環境でしたが、iTextSharpライブラリで実装に持っていくのに、かなりの時間が掛かってしまいました・・・。一体なぜ時間が掛かったのでしょう?
ライブラリの依存問題で時間が掛かった。
iTextSharpでも、PDFsharpと同じように依存関係のエラーメッセージが表示されました。先程と同じインポートの仕方で進めていくわけですけど、こんな感じのエラーメッセージが表示されます。
“0” 個の引数を指定して “Close” を呼び出し中に例外が発生しました: “ファイルまたはアセンブリ ‘BouncyCastle.Cryptography, Version=2.0.0.0, Culture=neutral, PublicKeyToken=072edcf4a5328938’、またはその依存関係の 1 つが読み込めませんでした。指定されたファイルが見つかりません。”
はい、ここで出てくるのが「BouncyCastle.Cryptography」というライブラリです。
BouncyCastleの表示バージョンと実際に必要なバージョンは違う。
「iTextSharp BouncyCastle.Cryptography」でググると、それに関する記事が色々と出てくるのですが、結局何をすると正解なのかがあんまり分かりませんでした。色々な方が困っているようすでした。
以下の記事のようなバージョンのiTextSharpライブラリに正しいバージョンのBouncyCastle.Cryptographyライブラリを持ってくると上手く動きそうですが、なんで別のDLLを持ってこないと動かない仕様になっているんでしょうか? いやそもそも仕様じゃなくてバグか?

「BouncyCastle.Crypto」のバージョンは「2.0.0.0」と表示されていたので、色々探して該当するバージョンを拾ってきたのですが、どうやら、この表示されているバージョンとは別のバージョンが動いていることもあるらしく・・・。(それは上記の記事に載っていました。)
そんな、実際に動いているバージョンの発掘までするのはスゴイ面倒だし、ああ、なんでこんなにも厄介な依存をしているのか全然意味が分からん・・・。
という風に、ネットサーフィンして眉を顰めてブー垂れながら色々と悪戦苦闘していたのですが、結局のところ、iTextSharpで動かすことに成功します。と言うか、こんなに「BouncyCastle.Crypto」で困っている人がいる傍らで、その点には全く触れていない記事も散見されたのを不思議に思っていたんですよね。
そこで、そのiTextSharpに関して、さざ波の「さ」の字も感じさせないような記事の更新日時を見て、その頃に最新だった「iTextSharp」ライブラリのバージョンで動かしてみたところ、上手く動きました。
僕が実際に動かすことが出来たiTextSharpのバージョンは、「5.5.13」です。(ちなみにポシャっていた時に使っていたバージョンは、「5.5.13.4」でした。)
ドキュメントがFAQばかりで時間が掛かった。
良かったです。iTextSharpでPDFを結合することは出来るようになりました。
しかし、そこから自分の頭の中にあるツールの形に持っていくのに、また少し時間が掛かりました・・・。
その原因は、コードを直すための情報を満足に集めることが出来ていなかったからでした。
iTextSharpもとい、iTextライブラリのドキュメント(?)のURLはここだと思いますが・・・。(.NET FrameworkでiTextSharpを使ってPDFを作成するサンプルコードが載っています。)
しかしこのドキュメントを放浪してみて、クラスやメソッドの抽象的なリファレンスが見つけられず、主にFAQベースの資料や、「Let’s Start iText !」的なサンプルコードばかりでした。なので、特定のプロパティを変更する方法が分からず、徒に時間だけが過ぎていきました・・・。悲しかった・・・。
しかし、そこで役に立ったのが生成AIでした。
「PDFの用紙のサイズを変えたい。」「余白をなくしたい。」と要望を出せば、解決案をすぐさま出してくれます。開発者用の抽象的なドキュメントはあった方がベターだとは思いますが、今日のような生成AI時代では、FAQ満載のドキュメントでもAIにしっかり学習させれば、とても有用な生き字引になるわけですね。(おそらく種々のWeb記事と併せて学習されているんでしょう。)
いやあ、この時代に生きてて良かったああ。
それではPDFを結合します。
ということで、「複数の画像をPDFに結合するだけ」のこんな単純なツールに多くの時間を使ってしまいましたが、自分の頭の中でイメージしていたものに合致しました。今回のPowerShell製ツールです。
function Merge-ImagesIntoPdfWithITextSharp([array]$imgPathList, [string]$iTextSharpPath) {
Unblock-File -Path $iTextSharpPath;
# [System.Reflection.Assembly]::LoadFrom($iTextSharpPath);
# Add-Type -Path $iTextSharpPath
Add-Type -LiteralPath $iTextSharpPath
# $error[0].Exception.GetBaseException().LoaderExceptions
$ext = ".pdf";
$pdfName = "{0}\{1}{2}" -f $imgPathList[0].DirectoryName, $imgPathList[0].BaseName, $ext;
Write-Output $imgPathList;
Write-Host ("{0}: hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh`n" -f $MyInvocation.MyCommand.Name);
Write-Output $pdfName;
$doc = New-Object iTextSharp.text.Document;
$pdfWriter = [iTextSharp.text.pdf.PdfWriter]::GetInstance($doc, [System.IO.File]::Create($pdfName))
$doc.Open()
# Get image files to add into PDF.
foreach ($path in $imgPathList) {
Write-Output $path;
Write-Output $path.GetType().FullName;
Write-Output $path.FullName.GetType().FullName;
Write-Host ("{0}: kkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkk`n" -f $MyInvocation.MyCommand.Name);
$image = [iTextSharp.text.Image]::GetInstance($path.FullName);
# Scale images to each page size.
$doc.SetPageSize($image);
$doc.NewPage();
$image.SetAbsolutePosition(0, 0);
# $image.ScaleToFit($doc.PageSize.Width, $doc.PageSize.Height);
$image.Alignment = [iTextSharp.text.Image]::ALIGN_CENTER;
$doc.Add($image);
}
$doc.Close();
$pdfWriter.Close();
}
$targetFolder = (Get-Location).Path;
$imgPathList = Get-ChildItem $targetFolder -Recurse -File -Include *.jpg -Exclude PDFsharp*;
$iTextFilePath = "{0}\lib\itextsharp.dll" -f $targetFolder;
Merge-ImagesIntoPdfWithITextSharp $imgPathList $iTextFilePath;
$tmp = Read-Host "Input 'y' if you wanna move original images......";このツールで、こんな感じにPDFを結合することが出来ました。余白を作らず、画像そのままのアスペクト比でPDF化することが出来ました。これでディスクのセクタの無駄遣いは減らせそうです。
他にも色々なPDFライブラリがあるみたいです。
この他にも、「PDFtk」というライブラリがありましたが、それはiTextSharpベースのライブラリみたいなので、自分には蛇足かなと思い、スキップしました。

あと、「CubePDF」のPDF結合用のライブラリがあったりするみたいなのですが、これはちょっと情報が少なそうだったので、同様にスキップしました。
そして、生成AIから「ImageMagick」というソフトウェアを紹介されましたが、これが何とも言えないぐらいに凄惨な状態になっていて・・・、
2024-11-03時点で、報告されている脆弱性の件数が、645件だそうです・・・。 これはマズイ・・・。

まとめ
今回は、PowerShellで複数枚の画像を1つのPDFファイルへと結合する方法を紹介しました。
以下、本記事のまとめです。
- 画像ファイルのサイズを小さく出来たのは良かったが、ディスクフラグメンテーションが発生した。
- そのため、複数の画像ファイルをPDFとしてまとめることにした。
- PowerShellを使えば、大量のファイルをより細かい設定で、1つのPDFに変換することが可能。
- 今回は、iTestSharp(ver. 5.5.13)ライブラリで実装した。それ以上のバージョンで実装すると、依存関係を解消する必要が出てくる可能性が高く、実装が大変になる。
これで、規定の用紙サイズに囚われずに、キレイなPDFを作るために課金をする必要は無くなります!
また、Macにあるアプリを使っても、規定の用紙サイズに囚われずにキレイなPDFを作れますが、PowerShellを使えば、Windows上でもそれが可能になりました。
PowerShell関連記事
その他のPowerShell関連の記事を貼っておきます。


おしまい
よし、これで画像を整理できる!
もっと手早く終わらせるつもりだったのになあ・・・。
以上になります!


コメント